DRLVM Jitrino即时编译器
DRLVM Jitrino即时编译器
参见: http://harmony.apache.org/subcomponents/drlvm/JIT.html
修订历史
版本 |
版本信息 |
日期 |
初版 |
Intel, Nadya Morozova: 创建文档. |
2006年6月5日 |
本文档描述了Jitrino即时编译器的内部结构,该组件是作为动态运行时层(Dynamic Runtime Layer, DRL)计划的一部分部署在虚拟机中。本文探讨即时编译器的内部结构设计和它与DRLVM其他组件的交互。通过本文档,读者可以了解即时编译器的具体实现细节。至于JIT在整个虚拟机设计中的作用和VM层的需求等一般的信息超出本文的讨论范围,这些内容参阅虚拟机源代码包中提供的DRLVM开发者指南。
本文面向的读者是对代码编译算法特别感兴趣的DRLVM开发者。文中的信息对DRL编译技术的进一步开发会有帮助,可以为那些从头开始实现JIT编译器的人提供范例。本文假设读者了解即时编译和优化算法等概念。
对DRLVM即时编译器从如下主要部分进行描述:
本文使用对DRL文档包的统一约定。
Jitrino是当前DRLVM所带有的即时(JIT)编译器[2]的代号。JItrino由两个不同的JIT编译器组成,它们共享源码并打包成一个库:
本文档描述了两种编译器和它们的操作。所有关于Jitrino的不含特定副标题(JET或OPT)的引用等同于对这两种编译器的引用。
JIT编译器的主要特点如下:
Jitrino.OPT还有如下特有的特点:
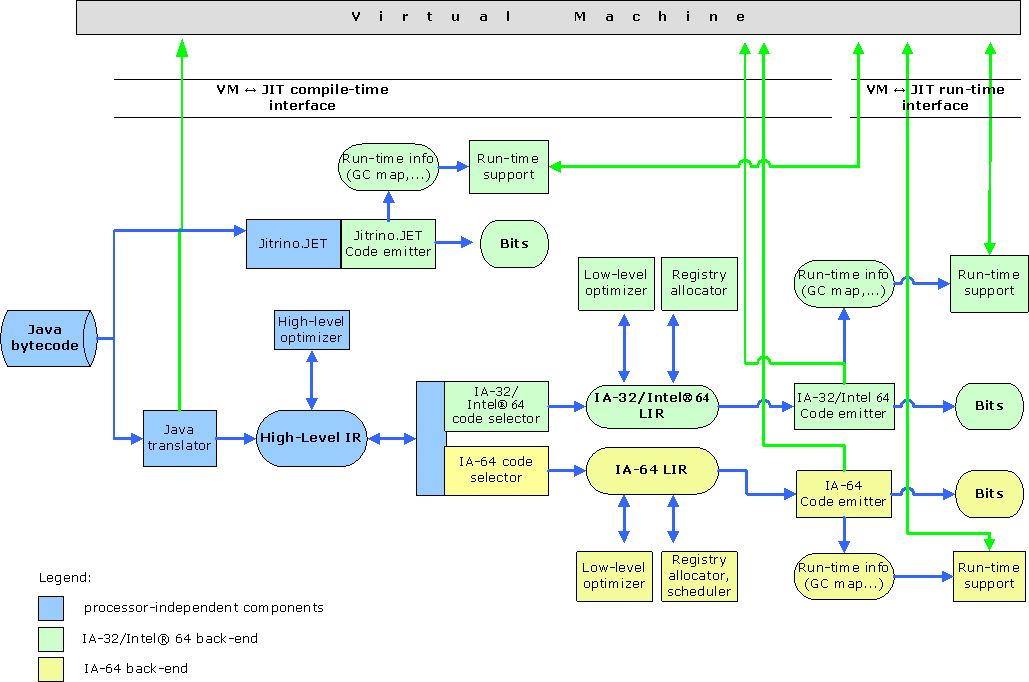
Jitrino编译器提供一些方法来编译和优化分发到Java*运行时环境的代码并使之适应不同的硬件体系结构。图1显示了编译器的结构和它们与虚拟机之间的交互。
Jitrino.JET和Jitrino.OPT编译器都有一个平台无关的前端和一个平台相关的后端。编译将它们连接起来并将前端从原始字节码中提取的类型信息传播到特定平台的后端。要想支持新的硬件平台就需要实现一个新的平台相关的后端。
Jitrino可以遵循不同的代码编译策略。编译过程的优化可以是为了获得最短的编译时间、为了获得最好的性能,还可以是可接受的编译时间和合理的性能的折中。编译过程可以包含Jitrino.JET基线编译器、Jitrino.OPT优化编译器或包含这两者。在很多应用中,只有很少的方法消耗了运行时的大部分时间,所以当Jitrino积极地优化这些方法时,还是能提高总体性能的。执行管理器(EM)定义实际的编译策略。
Jitrino.JET基线编译器通过将Java*字节码直接翻译成本地代码而提供最快的编译时间。此编译器执行的是快而简单的编译,几乎没有应用优化。
Jitrino.OPT— 重要的Jitrino编译引擎,它以牺牲较多的编译时间为代价,提供最优化的本地码。JItrino.OPT的编译过程也在图1中显示,重点集中在下列各项:
Jitrino的体系结构是模块化的,这使得实现更多的前端变得容易,比如公共语言基础(CLI)的字节码前端。
本文档描述了Jitrino.JET和Jitrino.OPT编译器的内部结构和运行在它们内部的处理过程。
{{ http://harmony.apache.org/subcomponents/drlvm/images/compilation_process.gif}} |
图 1. Jitrino编译器体系结构 |
本节描述了优化编译器Jitrino.OPT的内部结构。
流水线管理框架(pipeline management framework,PMF)定义了编译过程在Jitrino.OPT内部是如何执行的。在PMF下,编译过程表示成一条流水线(pipeline),它是步骤的线性序列。每个步骤存储对一个操作对象的引用、所需的参数和其他相关信息。操作(Actions)表示独立的代码变换,比如优化遍(pass)。流水线中不同的步骤可以引用相同的操作,例如,多次运行同样的变换。各流水线的步骤序列可以不同。
为了选择编译一个给定的Java*方法的流水线,系统使用由类名、方法名以及方法标记构成的方法过滤器作为选择标准。每一个JIT实例有一个公共的流水线,该公共流水线带有一个接受所有方法编译请求的空方法过滤器。除此之外,可以创建带有唯一且非空的过滤表达式的可选流水线来编译特定的Java*方法集。
Jitrino.OPT中的流水线用VM属性机制进行配置。PMF分析属性、构造流水线并向操作传递参数。因为OPT编译器没有“硬编码”(hard-coded)流水线,因此你需要在EM配置文件中或通过VM属性配置流水线。要使用Jitrino命令行接口和有效地运用Jitrino日志记录系统,需要理解流水线的配置规则。关于PMF内部的细节,参阅PMF详细描述。
本节定义编译器的主要部件。这仅是和主要编译阶段相匹配的抽象的、逻辑上的划分。每个逻辑组件包括在编译流水线中连续使用的操作。
翻译器
字节码翻译器负责把输入的字节码指令转换成高级中间表示(high-level intermediate representation,HIR)。这种IR比字节码的级别更低,它把复杂的字节码操作分解成几条简单的指令,从而为以后的高级优化阶段提供更多的优化机会。例如,加载一个对象域的操作被分解成以下操作:执行对象引用的空检查、加载对象的基址、计算域地址和加载所计算的地址中的值。
关于变换过程的细节,见3.2.1字节码翻译。
优化器
优化器包括一套独立于原始Java*字节码和硬件体系结构的优化。这里采用了一个针对Java*和CLI程序的单一优化框架。优化器执行一系列的变换遍对输入的高级中间表示进行优化。关于所应用的变换的描述,见3.2.2高级优化。
应用了高级优化(HLO)之后,代码选择器(code selector)把高级中间表示(HIR)转换成低级中间表示(LIR)。这个组件被设计使得不同体系结构的代码生成器(code generator,CG)能插入到编译器中。为了实现可插拔,代码生成器必须为一个方法的每个结构实体(比如整个方法、基本块和指令)实现代码选择器回调接口。在代码选择过程中,选择器使用回调接口把这些实体从HIR翻译成LIR形式。处理细节见3.2.3代码选择。
代码生成器
代码生成器(CG)负责生成不同于输入的高级中间表示的机器码。CG通过代码选择器回调接口接受HIR信息。关于结果代码是如何生成的细节,见3.2.4.代码生成。
代码生成器也执行一些辅助操作,比如:
中间表示是正被编译的代码的内部编译器表示。Jitrino.JET没有代码的中间表示,它直接把字节码编译成本地代码。Jitrino.OPT使用两种IR形式:高级中间表示(high-level intermediate representation ,HIR)和低级中间表示(low-level intermediate representation ,LIR)。为了编译一个方法的代码,Jitrino.OPT编译器把Java*字节码翻译成一个带有节点、边和指令的基于图的结构。图中的节点和边表示程序的控制流。图中每一个节点包含表示简单操作的指令。
例子:
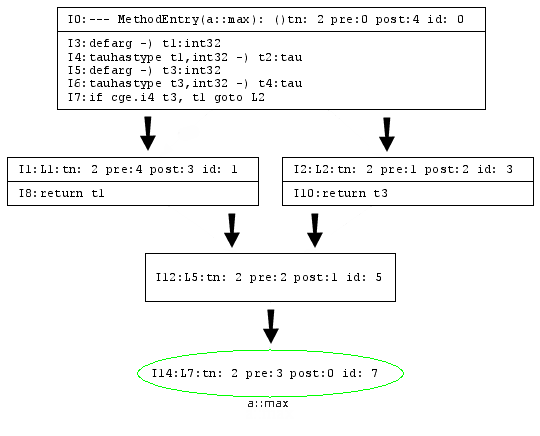
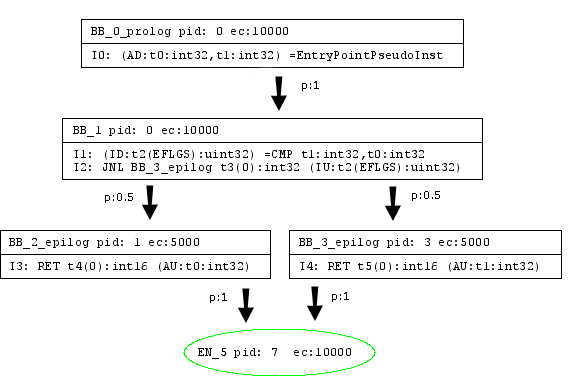
下面是一个代码实例,由相应的Java*代码、Java*字节码和用于Jitrino.OPT的高级、低级中间表示组成:
Java*代码:
public static int max(int x, int y) {
if (x > y) {
return x;
}
return y;
}
|
Java*字节码:
public static int max(int, int);
Code:
0: iload_0
1: iload_1
2: if_icmple 7
5: iload_0
6: ireturn
7: iload_1
8: ireturn
|
代码的Jitrino高级中间表示:
{{ http://harmony.apache.org/subcomponents/drlvm/images/HIR.png}} |
代码的Jitrino低级中间表示:
{{ http://harmony.apache.org/subcomponents/drlvm/images/LIR.png}} |
HIR和LIR均使用一个公共的控制流图结构和相应的算法;参见5.4.控制流图。本节将详细描述当前在Jitrino中使用的两种中间表示。
高级IR
Jitrino高级中间表示(HIR)是被编译代码的平台无关的表示。在HIR中,每一个基本块节点由指令列表组成,每一条指令包括一个操作符和一组操作数。HIR支持静态单赋值(single static assignment,SSA)形式,其中每一个操作数恰好有一个赋值。SSA形式在操作数和定义它们的指令间提供显示的use-def(使用-定义)链,这简化和加速了高级优化。在以后的编译阶段,每一条HIR指令和每一个操作数把详细的类型信息传播到后端。
编译器也维护HIR上的支配者和循环的结构信息以备优化和代码生成阶段使用。
低级IR
Jitrino低级中间表示(LIR)特定于实现它们的代码生成器。{{Jitrino IA-32/Intel? 64 CG LIR}}的细节不同于HIR,它不支持SSA形式,其设计非常接近于IA-32和Intel? 64体系结构。
本节描述在Jitrino优化编译器内部进行的主要处理过程。
初始的编译步骤是将字节码翻译成HIR,它包括以下两个阶段:
字节码翻译器建立基本块边界和异常处理区域,并为变量和操作符推断类型信息。在本阶段,与JVM规范中描述的字节码验证算法\[1\]相类似,翻译器为变量和虚拟Java[\*|#node]栈存储单元生成类型信息[\[1|#ref1]]。 |
高级优化是优化器执行的平台无关的变换。优化器应用一套能平衡优化效果和编译时间的经典的面向对象优化。每一个高级优化表示成一个HIR上的独立变换遍。每个Jitrino.OPT优化有如下的一个或多个目标:
优化模式
Jitrino高级优化器支持各种优化模式,优化模式根据优化路径和用于优化代码的profile信息来进行划分。不同的优化模式专用于不同的应用类型:客户应用程序通常要求快的启动时间和合理的响应时间,然而从长远来看服务器应用程序要求最高级的性能。一个特殊的优化模式定义如下:
在执行管理器配置文件中保存有几个预定义的Jitrino优化模式,如下:
-Xem:server
|
本部分定义当前在Jitrino.OPT编译器中可用的所有优化。相关的优化被收集成组,如下所示:
作用域增强遍(Scope Enhancement Passes)
高级优化始于一套增强进一步优化的作用域的变换,如下所示:
下面的例子说明了内联算法。
Inline(HIR_of_compiled_method) {
current_bytecode_size = HIR_of_compiled_method.get_method().bytecode_size()
find_inline_candidates(HIR_of_compiled_method)
while (true) {
callee = NULL
while (!inline_candidates.empty()) {
callee = inline_candidates.pop()
callee_bytecode_size = callee.bytecode_size()
if ((current_bytecode_size + callee_bytecode_size) < SIZE_THRESHOLD) {
current_bytecode_size += callee_bytecode_size
break;
}
}
if (callee = NULL) {
break;
}
HIR_of_callee = Translator.translate(callee)
Optimizer.optimize(HIR_of_callee, inliner_pipeline)
find_inline_candidates(HIR_of_callee)
HIR_of_compiled_method.integrate(HIR_of_callee)
}
}
find_inline_candidates(method_HIR) {
foreach direct_call in method_HIR {
inline_benefit = compute_inline_benefit(direct_call)
if (inline_benefit > BENEFIT_THRESHOLD) {
inline_candidates.push(direct_call)
}
}
}
|
冗余消除遍(Redundancy Elimination Passes )
本套优化旨在消除冗余的和部分冗余的操作。如果JIT能证明一些操作是冗余的并且没有任何副作用,则这些操作可从代码中删除。通过这种方式,节省了冗余操作的执行时间,加快了目标代码的执行。该优化组由以下遍组成:
HIR简化遍(HIR Simplification Passes)
HIR简化遍是一套快速优化方法:Jitrino优化器对中间表示执行多次优化以减小其大小和复杂性。简化遍提高了代码质量和高代价优化的效率。HIR简化被分组成一系列在优化路径中的不同点执行的简化遍。
静态profile估计器(Static profile estimator,statprof)
许多优化能使用边profile信息提高效率。当执行管理器配置为使用动态profiling模式时,profile由JIT来收集。但是即使在静态模式下,当动态profile不可用时,Jitrino.OPT能使用statprof优化遍更新HIR,其中使用的profile信息是基于启发式的。在动态profiling模式下,一些优化由于改变了CFG结构可能破坏profile信息。在这种情况下,使用statprof可以修正profile信息,保持它的一致性。
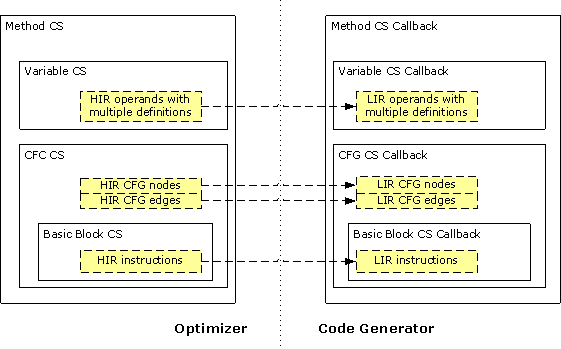
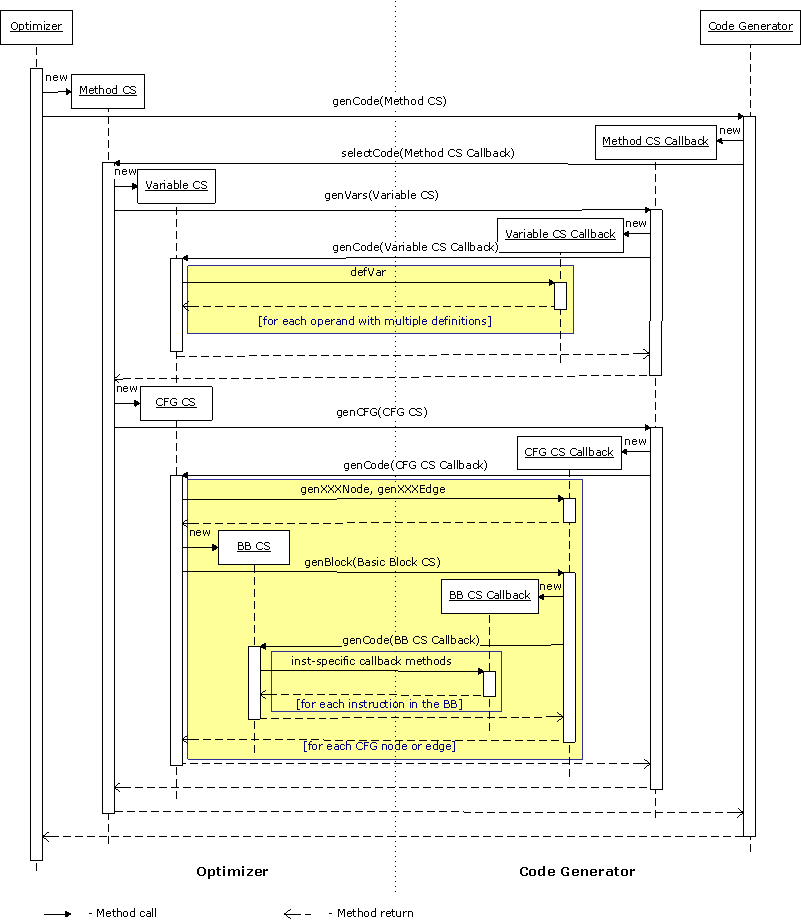
在优化遍之后,HIR被翻译成LIR。代码选择(CS)是基于被编译的方法的HIR层次结构的,如图2.所示。
{{ http://harmony.apache.org/subcomponents/drlvm/images/code_selector.gif}} |
图 2. 代码选择器框架 |
其中:
对于方法、多重定义的操作数集合、控制流图和CFG基本块节点的集合,代码选择器框架定义如下:
因此,CS框架在优化器和可插拔的代码生成器之间建立了一个良定义的边界。同样,代码选择器框架也提供对IR变换的结构化方法,这样CG能在不同层次上重写它。
图3.显示了代码选择的过程,其中循环用黄色突出显示。
{{ http://harmony.apache.org/subcomponents/drlvm/images/code_selection_seq.gif}} |
图 3. 代码选择顺序图 |
图3说明了变换过程的具体过程,分析如下:
代码生成过程特定于实现它的可插拔代码生成器。本节简要介绍{{Jitrino IA-32/Intel? 64}}代码生成器的当前实现,以及为确保它是线程安全的所做的度量。
为了为一个方法生成代码,代码生成器需要做大量工作,其执行步骤粗略地分成以下阶段:
LIR创建
在本阶段,代码生成器在代码选择器回调接口的实现中创建与输入的HIR相对应的LIR。所得的LIR是十分紧凑的,它具有以下五条性质:
1. 大部分2操作数指令被生成为带有一个独立目的操作数的扩展的3操作数形式。
2. 每个调用点表示成单个指令,而没有为被调用者参数显式地创建调用栈。
3. 用伪指令(宏)表示64位整数运算。
4. 地址计算大部分是显式的而没有使用复杂地址形式。
5. 大部分操作数复制指令用伪指令表示,对其操作数不强加任何限制条件。
LIR变换
在本阶段,代码生成器对LIR执行大量变换和优化,如下所示:
1. 在某些循环的后退分支中插入退让点以使线程可以安全挂起。
2. 执行第一遍GC安全点分析,变换代码以确保在代码生成过程的最后创建正确的GC映射图而不考虑处理过程中的变换。
3. 根据需要把地址运算合并成复杂的地址形式。
4. 使用一些优化把64位整数运算的伪指令扩展到真正的本地指令序列。
5. 把LIR指令从扩展的3地址形式翻译成本地的2地址形式。
6. 分析指令和调用规约。基于分析结果,代码生成器划分操作数以便每个操作数在其使用的地方满足指令的约束条件。
7. 执行全局寄存器分配将大部分频繁使用的操作数分配到通用寄存器或XMM寄存器。
8. 考虑指令约束,执行局部寄存器分配和每个基本块上的溢出代码生成。这一遍确保所有操作数被赋值到物理单元,即在寄存器中或在栈上。同时该遍也将生成没有预先全局寄存器分配的正确代码。
9. 根据profile信息线性化所有可线性化的CF G基本块。
10. 把复制伪指令扩展到真正的本地指令序列中。合并具有非重叠活跃范围的栈操作数的副本。
11. 检查栈布局以便将偏移分配给栈操作数和创建栈布局描述。
实际的代码生成过程也可以包括不同的优化遍,比如常量和复制传播、死代码删除和冗余比较删除。优化通过EM配置文件和命令行接口进行。
代码和数据发射(Code and Data Emission)
在本阶段,代码生成器做必要的准备并把LIR转换成机器码,具体如下:
全局锁
因为在当前VM实现中内存分配例程不是线程安全的,因此Jitrino为代码生成阶段设置了一个全局锁,以确保为编译的方法数据正确分配内存。当在多线程环境下工作时,必须考虑全局锁,比如,同时在几个线程启动一个方法的编译时。全局锁在Jitrino.JET和Jitrino.OPT之间共享,它确保一次只有单个线程尝试为一个方法分配内存。锁由lock_method Action对象获得,由unlock_method Action对象释放。
Lock_method操作也检查当前JIT实例是否已经为正被编译的方法分配一个代码块。如果该代码块已经被分配,则这个方法已经在另一个线程中编译。在这种情况下,lock_method操作不是设置锁,而是停止编译进入COMPILATION_FINISHED状态。操作unlock_method通过lock_method操作释放已获得的锁。
全局锁强加以下要求:
Jitrino.JET基线编译器是Jitrino的子组件,用于将Java*字节码几乎不带优化地翻译成本地代码。这个编译器通过组合本地栈和寄存器来仿真基于栈的机器操作。
在代码生成阶段,方法的操作数栈的状态是拟态的。这种状态有助于计算GC映射图,它用于以后运行时支持GC操作。
GC映射图表明局部变量或栈槽上是否包含一个对象。每当定义对一个局部槽的操作时,局部变量的GC映射图都要进行更新,如下所示:
栈的GC映射图只有在GC点进行更新,也就是在一条可能导致GC事件的指令之前,比如,一个VM helper调用。在方法编译期间计算出来的栈的深度和状态在调用前得到保存:通过生成代码来保存状态。状态保存到方法的本地栈中预先分配的特定区域。这些区域包括GC信息,也即操作数栈的深度、栈的GC映射图、局部变量的GC映射图。
此外,Jitrino.JET为每个方法在编译期间准备和存储一个特定的结构:方法信息块。这些结构以后用来支持运行时操作,比如栈展开、字节码和本地代码之间的映射。
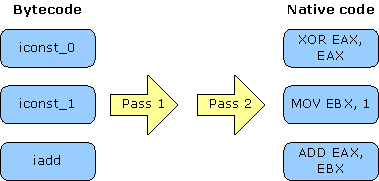
基线编译是带有极小优化的编译代码过程。Jitrino.JET的子组件按如下描述执行操作:
Jitrino.JET在字节码上执行两遍,如图4所示。第一遍建立基本块边界,第二遍生成本地代码。
{{ http://harmony.apache.org/subcomponents/drlvm/images/bytecode_to_native.gif}} |
图 4. 基线编译路径 |
下面是对这两遍的描述。
第一遍
在一个方法的字节码上执行第一遍时,编译器得到基本块的边界和它们的引用计数。
注意:
这里的_引用计数_是指到达一个基本块(BB)的路径数。
为了得到基本块的边界,Jitrino.JET对字节码进行一次线形扫描并用如下规则来分析指令:
在第一遍中,编译器还为每个块算出引用计数。
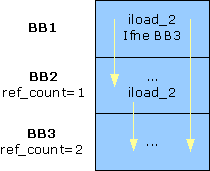
例子:
图5是一个关于引用计数的例子。第二个基本块(BB2)的引用计数ref_count=1,因为它只能由第一个基本块(BB1)到达。第三个基本块的引用计数是2,因为它既可以作为BB1的分支目标到达也可以从BB2直接到达。
{{ http://harmony.apache.org/subcomponents/drlvm/images/reference_count.gif}} |
图 5. 基本块的引用计数 |
Jitrino.JET在代码生成期间利用引用计数来减少转存数量。
第二遍
在第二遍执行中,Jitrino.JET完成代码生成,如下所示:
1.对第一遍获得的基本块按照深度优先搜索顺序进行处理
2.为每条字节码指令生成代码并模拟Java*操作数栈
3.匹配本地码布局和字节码布局
4.更新相对寻址指令,如CALL和JMP指令
关于基线编译的实现细节,参阅用{{Doxygen}}从源码生成的文档。
JIT编译器依赖于下面的实用程序:
JIT编译器的实用程序和VM的实用程序类似,但并不完全相同。例如,JIT编译器和虚拟机内核使用不同的日志记录程序。
在Jitrino.OPT编译器中,使用常规的内存管理器例程进行内存分配。这种机制保证在编译过程中分配的所有内存在编译结束后被释放。此外,内存管理器通过使用快速的线程局部内存分配算法来减少系统调用的次数。重载内存分配的内存管理器代码和操作在{{jitrino/src/shared/directory}}中的{{.h}}和{{.cpp}}文件里。
要开始使用内存管理器,一个JIT编译器的开发者必须创建一个内存管理器实例,它能提供初始堆大小和用于记录日志的名字。
内存管理器从操作系统那在叫做{{arenas}}的大块中分配内存。在{{MemoryManager}}中,一个{{arena}}块的最小大小是4096个字节。当JIT编译器要为一个对象分配内存时,从当前{{arena}}块分配内存而无需系统调用。如果当前{{arena}}没有足够的空闲空间,内存管理器就从另外一个{{arena}}进行分配。
下面是一个使用{{MemoryManager}}类的典型模式。
void optABC() {
//the temporary memory manager used for optABC optimization data
MemoryManager tmpMM(10000, "mm::optABC");
StlVector<int> myData1(tmpMM, 1000);
int* myData2 = new (tmpMM) int[1000];
//JIT compiler code follows
}
|
用内存管理器分配的内存在它的析构函数中释放,而用内存管理器分配的对象却不调用析构函数。内存管理器的这一特点要求JIT编译器代码中满足下列规则:
1.不能使用另一个_内存管理器_来分配一个{{MemoryManager}}对象,否则,{{MemoryManager}}的内存将永远不会被释放。
2.谨慎地混合由不同内存管理器分配的对象。这种对象的生命期可能是不同的。
3.用{{MemoryManager}}分配的对象的析构函数从不会被调用。让析构函数为空。
4.为了避免内存溢出错误,记住{{MemoryManager}}分配的内存只有当{{MemoryManager}}销毁时才会被回收。
Jitrino.OPT有两个专用的内存管理器:
使用{{MemoryManager}},你可能无法得到关于内存破坏的系统通知。
例子
当一个值被存到超过下标范围的数组元素中时,可能发生内存破坏:
MemoryManager tmpMM(10000, "myMM");
int* myData2 = new (tmpMM) int[10];
myData[10] = 1;
|
这段代码可以成功地执行是因为内存管理器分配的默认内存块的大小比数组大小要大。
为了能够检测到内存破坏错误,在{{MemoryManager.cpp}}文件中定义了宏{{JIT_MEM_CHECK}}。在这个宏定义之后,内存管理器为所有的{{arena}}空间填写预定义的值并在对象之间添加填充空间。每次分配一个对象时,内存管理器都检查{{arena}}中的这些预定义的值。如果在限制区域内执行了写操作,内存管理器就会报错。
Jitrino维护_计数器_(counters)来收集统计数据。计数器可以用于任一Jitrino操作中,在整个VM执行期间,对所有流水线中的一个特定的事件进行计数。每个计数器都有一个名字以区别于其他计数器。
要计算一个Jitrino操作的总执行时间,Jitrino也提供了_计时器_(timers),它是计数器的一个特殊形式。要激活计数器和时间度量,可使用下面的命令语法。
-XDjit.<JIT>.arg.time=on
|
注意:
该选项默认情况下为off。
每一操作的所有实例的执行时间被单独进行测量,在VM停止运转时进行汇总。操作执行时间的结果数据都被写到一个表格中并按操作名进行分类。
注意:
通常,要输出操作执行时间和计数器值表,你需要指定下面的VM命令行选项。
–XcleanupOnExit
|
Jitrino的日志记录系统做如下工作:
日志记录系统是Jitrino PMF的一个主要的部分。日志记录由两个接口组成:
日志记录系统是基于_流_的。每个流都有一个名字用来在程序和命令行选项中对它寻址。Jitrino为几个经常使用的流提供预定义的名字。下面的这些流启用时能够产生特定的输出:
名字 |
输出 |
|
编译协议:JIT和流水线名字,方法名和数量等 |
|
与编译方法无关的运行时输出 |
|
编译时诊断 |
|
转储对一个已编译方法的内部Jitrino结构 |
|
用.dot格式转储内部Jitrino结构 |
|
调试信息 |
日志记录命令的通用语法遵循下面的PMF规则:
-XDjit.<JIT>.<pipeline>.arg.<path>.log=<list of stream names>
|
在这个命令语法中,<path>代表被启用的流的Jitrino操作集。当不指定具体路径时,这个命令可以应用到所有现存的操作中。
例子:
为了使所有JIT的所有流水线能启用编译协议,键入:
-XDjit.arg.log=info
|
为了转储编译时的诊断信息和IR 转储,键入:
-XDjit.arg.log=ct,irdump
|
要调试JIT,需要为编译的方法提供编译阶段间的[控制流图|#控制流图]的修改信息,包括指令和操作数。Jitrino编译器能够生成表示两个IR级的控制流图的dot文件。.dot文件能被转换成描述性的图,就是CFG的图形表示,见3.1.3节[中间表示|#中间表示]中的用图形来可视化代码的例子。对于.dot文件的转换有各种各样的图形可视化工具可用,比如Graphviz\[6\]。 |
用下面的命令能够转储 .dot文件
-XDjit.arg.log=dotdump
|
关于Jitrino日志记录系统的更多细节,参阅PMF描述中的相应部分。
高级和低级中间表示用一个统一的基本结构来表示一个编译的方法的逻辑结构,就是_控制流图_(CFG)。这种统一使得Jitrino可以避免其内部中的代码复制,减少代码大小和改进所生成的代码质量。
当前的CFG实现在{{jitrino/src/shared/ControlFlowGraph .h}}和{{.cpp}}文件中。这些文件包含CFG的核心结构和算法,并且能被直接重用和扩展自定义的功能。
控制流图实现的目标是提供下列各项:
控制流图支持两类控制流:
因为IR可以表示异常控制流,优化器和代码生成器考虑这点来对异常和异常处理程序进行优化。在控制流图中,对异常控制流的显式建模使得编译器可以跨越多个抛出-捕获边界进行优化。对于局部处理的异常,编译器可以用代价更低的直接分支来代替代价高的抛出-捕获组合。
CFG的结构有节点、边和指令,分别用{{Node}}、{{Edge}}和{{CFGInst}}类表示。
子类化
所有的CFG类可以被用户代码子类化。{{CFGInst}}类有纯虚函数,所以在使用前必须子类化。{{Node}}和{{Edge}}类可以被子类化并扩展任意的用户数据,除了那些有限制的不能被扩展的节点和边类型之外。
节点
CFG使用下面几种节点:
此外,CFG还有专门的块和分派节点。Entry块节点标记方法的开始并支配图中所有的节点。可选的Return块节点被所有的正常路径支配,反之,可选的Unwind分派节点被方法引出的所有异常路径支配。Return和Unwind节点总是有且仅有一个出边,它总是指向Exit节点。
边
一条边连接两个节点,它的类型依赖于它连接的节点类型,在运行时被计算。如下所示:
指令
每个节点维持一个指令链表,它为节点的出边提供边的类型信息。指令接口也含有一些函数提供关于决定一条指令在一个节点中位置的信息,这些信息可以在运行时被CFG算法检查。指令是CFGInst类的子类。
当在当前上下文中指令类型信息不清楚时,CFG就从一个节点的最后一条指令来获得这些信息。例如,对于有两条或多条连接块节点的边的分支,边的类型总是从块的最后一条指令获得。当删除或重定位一条边时,会通知块中的最后一条指令去跟踪CFG的变化。相反,对于一条连接块节点和分派节点的边,很清楚这条边是Dispatch类型且不会发送任何请求。
对于一个节点,当一条普通指令在一条.h的临界指令之前被预先考虑时,指令的位置信息被用来跟踪可能的错误。.h临界指令包括异常捕获、方法前导指令和在HIR中用于标记节点的标签指令。
当前的CFG实现提供如下的图算法:
对于每个算法的细节,参阅用{{Doxygen}}从{{ControlFlowGraph.h}}文件生成的文档。
一个支配树表示为一个控制流图计算的(被)支配信息。该树能用来查询或操纵节点间的支配关系。树根是图中进入或退出节点的DominatorNode。除了根节点,任何支配者节点的双亲就是直接支配者或被支配者。
支配树的源文件是{{jitrino/src/shared/DominatorTree.h}}和{{.cpp}}。
注意:
当基本的CFG被修改后,支配树就无效了。虽然仍可以查询和操纵支配树,但支配树可能不再反映控制流图的当前状态。
一个循环树包含控制流图中的循环信息。它用来查询控制流图中的每个节点的循环信息。循环树用 LoopTree 和 LoopNode 类来表示。每个 LoopNode 类实例在图中都有一个关联的节点且代表一个循环的开头。 LoopNode 的所有孩子节点都是嵌套循环的循环开始节点。循环树的根节点是一个人为的节点用来连接方法的顶层循环和它的孩子节点。
循环树的源文件在{{jitrino/src/shared/LoopTree.h}} 和{{.cpp}}文件中
注意:
当基本的CFG改变时,循环树是无效的。在CFG修改后,你就不能操纵循环树。
本节描述JIT编译器输出的、用于和其他组件交互的接口。Jitrino公开所有必要的接口并作为运行时环境的一部分工作。Jitrino显式地支持精确的移动垃圾收集器,它要求JIT能枚举出活引用。
这个接口包括JIT编译器输出的、用于和虚拟机内核组件进行交互的函数。在JIT_VM接口内部的函数分成如下几类:
字节码编译
这个集合中的函数负责运行即时编译这个主要的JIT编译器任务,它由一个方法字节码产生本地可执行代码。编译方法的要求可以来自于VM内核或执行管理器。这个接口中每个函数的具体细节,参阅用{{Doxygen}}为{{vmcore /include /jit_export.h}}生成的文档。
根集枚举
这个函数集通过枚举和报告活对象引用来支持垃圾收集器。JIT编译器提供函数来报告那些在JIT编译的代码中的给定位置存活的对象引用和内部指针的位置。对象引用和内部指针组成了根集,GC用它来遍历所有的活对象。这个接口要求报告值的位置而不是值,使移动的垃圾收集器在移动对象时能够更新位置。
注意:
与那些总指向对象头的引用指针不同,内部指针实际上指向目标对象内的一个域。如果JIT报告出有内部指针而没有引用指针,这时GC实际上要负责重新构建引用指针。
关于GC相关活动的更多信息,参考开发者指南中的 根集枚举 和 垃圾收集器 部分。这个接口中每个函数的具体细节,参阅用{{Doxygen}}为{{vmcore/include/jit_export_rt.h}}生成的文档。
栈展开
虚拟机要求编译器支持栈展开的执行,即在栈上从被管理帧到调用者帧的一次迭代。
为了便于栈遍历,JIT的栈展开接口要做如下工作:
注意:
根集列举和栈展开是只能在执行被编译的代码时才能被调用的运行时例程。
JVMTI支持
负责JVMTI支持的JIT函数集是与虚拟机JVMTI组件交互的出口。这些函数做如下工作:
对于VM内核输出的、用于和JIT编译器交互的函数描述,参阅开发者指南中的 虚拟机内核公共接口 文件。关于构成每个接口组函数的细节,参阅用{{Doxygen}}为{{vmcore/include/jit_export_jpda.h and vmcore/include/jit_export.h}}生成的文档。
JIT编译器输出这个接口来支持执行管理器。这些函数集负责如下操作:
关于执行管理器输出的、用于与JIT编译器交互的出口,参见执行管理器描述中的公共接口部分。
关于JIT输出给EM的函数细节,参阅用{{Doxygen}}为{{include/open/ee_em_intf.h}}生成的文档。
\[1\] Java[\*|#node] Virtual Machine Specification, http://java.sun.com/docs/books/vmspec/2nd-edition/html/VMSpecTOC.doc.html <ac:structured-macro ac:name="anchor" ac:schema-version="1" ac:macro-id="f2db3153-dbdd-48b6-80a6-8d0f42f94ea1"><ac:parameter ac:name="">ref1</ac:parameter></ac:structured-macro> |
\[2\] JIT Compiler Interface Specification, Sun Microsystems, http://java.sun.com/docs/jit_interface.html <ac:structured-macro ac:name="anchor" ac:schema-version="1" ac:macro-id="32881ac4-43cb-4dd5-9f2f-23c5638382ba"><ac:parameter ac:name="">ref2</ac:parameter></ac:structured-macro> |
\[3\] S. Muchnick, Advanced Compiler Design and Implementation, Morgan Kaufmann, San Francisco, CA, 1997. <ac:structured-macro ac:name="anchor" ac:schema-version="1" ac:macro-id="4b03ae7e-500a-4297-b6f1-7ef6124bfc5d"><ac:parameter ac:name="">ref3</ac:parameter></ac:structured-macro> |
\[4\] P. Briggs, K.D., Cooper and L.T. Simpson, Value Numbering. Software-Practice and Experience, vol. 27(6), June 1997, http://www.informatik.uni-trier.de/~ley/db/journals/spe/spe27.html <ac:structured-macro ac:name="anchor" ac:schema-version="1" ac:macro-id="e9300212-689d-4fd1-8432-188a2ed646bd"><ac:parameter ac:name="">ref4</ac:parameter></ac:structured-macro> |
\[5\] R. Bodik, R. Gupta, and V. Sarkar, ABCD: Eliminating Array-Bounds Checks on Demand, in proceedings of the SIGPLAN ’00 Conference on Program Language Design and Implementation, Vancouver, Canada, June 2000, http://portal.acm.org/citation.cfm?id=349342&dl=acm&coll=&CFID=15151515&CFTOKEN=6184618 <ac:structured-macro ac:name="anchor" ac:schema-version="1" ac:macro-id="e333b044-0902-423c-8fc7-ca637715c364"><ac:parameter ac:name="">ref5</ac:parameter></ac:structured-macro> |
\[6\] Graphviz, Graph Visualization Software, http://www.graphviz.org/ <ac:structured-macro ac:name="anchor" ac:schema-version="1" ac:macro-id="48311d8e-ee49-49bc-bb4f-5558ff1a6c85"><ac:parameter ac:name="">ref6</ac:parameter></ac:structured-macro> |
Contributors:
张 昱(yuzhang@ustc.edu.cn)
袁丽娜(yln@mail.ustc.edu.cn)
郝允允(haoyy@mail.ustc.edu.cn))
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}