...
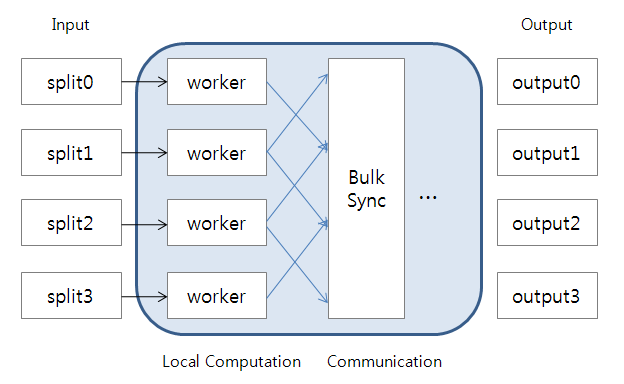
Let's see more detail in the diagram of computing method of Hamburg based on BSP model.
Wiki Markup
{kind=link}
Each worker will process the data fragments stored locally. And then, We can do bulk synchronization using collected communication data. The 'Computation' and 'Bulk synchronization' can be performed iteratively, Data for synchronization can be compressed to reduce network usage. The main difference between Hamburg and M/R is that Hamburg does not make intermediate data aggregate into reducer. Instead, each computation node communicates only necessary data into one another. It will be efficient if total communicated data is smaller then intermediate data to be aggregated into reducers. Plainly, It aims to improve the performance of traverse operations in Graph computing. unmigrated-wiki-markup
For example, to explores all the neighboring nodes from the root node using Map/Reduce (FYI, \[http://blog.udanax.org/2009/02/breadth-first-search-mapreduce.html Breadth-First Search (BFS) & MapReduce\]), We need a lot of iterations to get next vertex per-hop time.
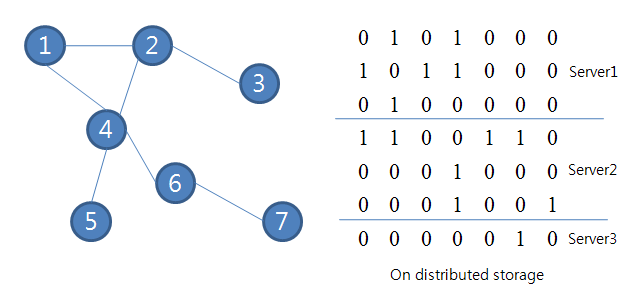
Let's assume the graph looks like presented below:unmigrated-wiki-markup
\[http://lh5.ggpht.com/_DBxyBGtfa3g/SmQTwhOSGwI/AAAAAAAABmY/ERiJ2BUFxI0/s800/figure2.PNG\]
{kind=link}
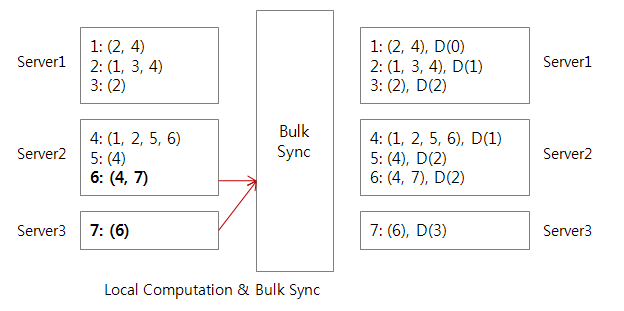
The root node is 1. Then, we need only one 'Bulk synchronization' between server2 and server3 with Hamburg. Rests will be calculated on local machine.
Wiki Markup
{kind=link}
Initial contributors
- Edward J. (edwardyoon AT apache.org)
- Hyunsik Choi (hyunsik.choi AT gmail.com)
...