Compare to kylin architechture, the main changes include the following:
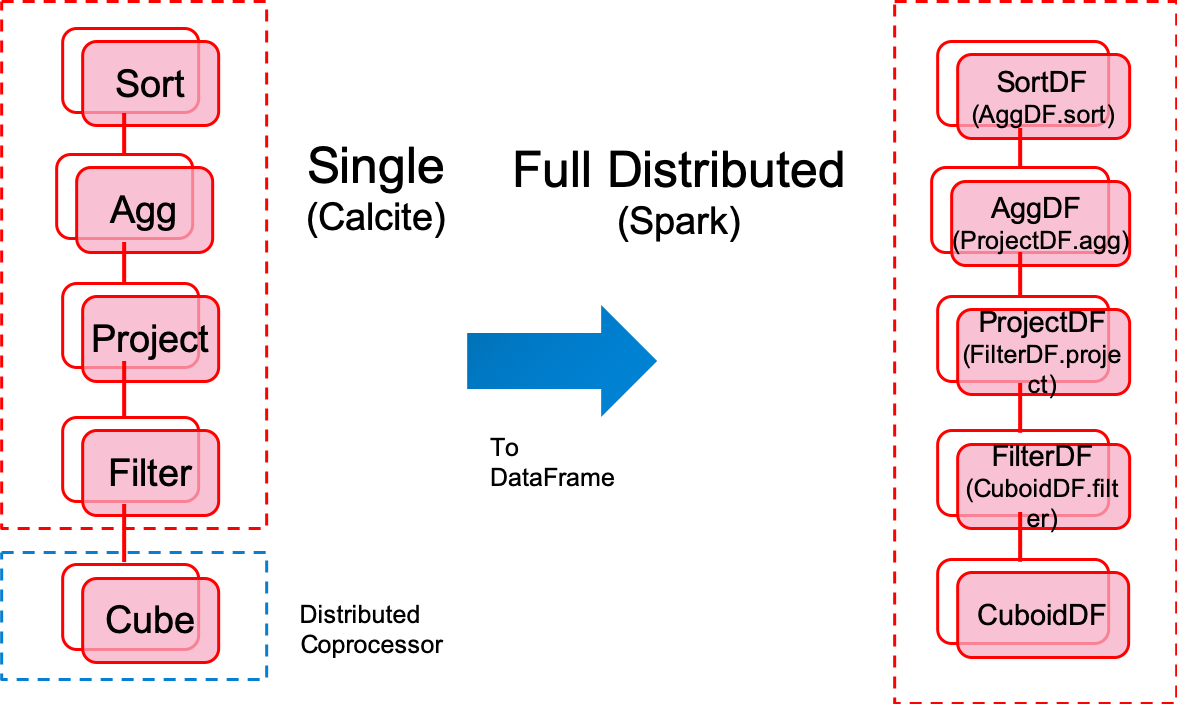
Fully distributed query engine. Query task will be sumbit to spark.
Spark as the only build engine.
Metadata still can be saved into HBase, RDBMS. There's a little difference with kylin metadata, see more from MetadataConverter.scala.
Cuboids are saved into HDFS as parquet format(or other file system, no longer need HBase)

Currently(before Kylin 4.0), Kylin uses Apache HBase as the default storage. HBase Storage is very fast, while it also has some drawbacks:
Kylin 4.X is going to use Apache Parquet(with Spark) to replace HBase, because:
The new build engine is faster and cost less storage space in file system. And the query engine also has a very good performance. See more with the performance from the following.
Benchmark Report for Parquet Storage
If contains COUNT_DISTINCT measure(Boolean)
Resource paths(Array) we can using ResourceDetectUtils to Get source table infor(like source size, etc).
Table RDD leaf task numbers(Map). It's used for the next step -- Adaptively adjust spark parameters
Turned on by default
Cluster mode only
Affect spark configuration property
kylin.engine.spark-conf.spark.executor.instances kylin.engine.spark-conf.spark.executor.cores kylin.engine.spark-conf.spark.executor.memory kylin.engine.spark-conf.spark.executor.memoryOverhead kylin.engine.spark-conf.spark.sql.shuffle.partitions kylin.engine.spark-conf.spark.driver.memory kylin.engine.spark-conf.spark.driver.memoryOverhead kylin.engine.spark-conf.spark.driver.cores |
The following is the tree of parquet storage directory in FileSystem. As we can see, cuboids are saved into path specified by Cube Name, Segment Name and Cuboid Id.

If there is a dimension combination of columns[id, name, price] and measures[COUNT, SUM], then a parquet file will be generated:
Columns[id, name, age] correspond to Dimension[2, 1, 0], measures[COUNT, SUM] correspond to [3, 4]