Project |
Implementing XML Schema 1.1 overriding component definitions (<xs:override>) |
|
Student Name |
Udayanga Wickrmasinghe |
|
mastershield2007@gmail.com |
|
|
TimeZone |
GMT +5.30 |
|
Abstract
Apache Xerces2-J consists of a set of standards compliant XML parsers and a [1] XML Schema processor which are built on top of a complete framework(XNI) for building parser components and configurations that is extremely modular. Although Xerces XML Schema processor supports more than the minimal requirement under W3C XML Schema 1.1 [2] specification some vital schema component support is still to be realized. This project tries to implement one such requirement, namely xs:override support for XML Schema1.1 .
Description
XML schema specification version 1.1 specifies syntax and semantics of “Overriding component definitions<override>”[3] or xs:override, under “Schemas and Namespaces: Access and Composition” . The new component definition is a powerful addition to the XML schema composition framework which tries to mitigate some of the constraints present in similar constructs such as xs:redefine or <redefine> schema components. The <redefine> construct defined in “Including modified component definitions (<redefine>) “[4] on XMLSchema specification is useful in schema evolution and versioning. It can be used only when there exists some restriction or extension relation between the old component and the new redefined component. But there are occasions when the schema author simply wants to replace old components with new ones without any constraint. Also, existing XSD processors have implemented conflicting and non-interoperable interpretations of <redefine>. And to add to the the inflexibility , <redefine> construct is declared •deprecated• in XML Schema 1.1 [2]. Hence as mentioned in the beginning , <override> construct tries to avoid these bottlenecks and allow unconstrained replacement as and when needed.
- According to the XMLSchema 1.1 specification xs:override schema component is specified in the following form (override information item) ,
<override id = ID schemaLocation = anyURI {any attributes with non-schema namespace . . .} > Content: (annotation | (simpleType | complexType | group | attributeGroup | element | attribute | notation))* </override>- .Here “schemaLocation” indicates the location of the overriden schema document while “Content” corresponds to the types/groups/attributes/elements this schema will be overriding on the schemas available at corresponding “schemaLocation” . xs:override semantics are very much similar to class/prototypical inheritance where after successful application , corresponding overridden schemas replaces their old schemas by the new overriding schemas contained within a <xs:override> element. Following describes the criteria of xs:override on a general overview. Implementing thsese sematics on XML schema composition framework ,can be be considered the main objective of the project.
1.override only applies if the schema component within <xs:override> exists in the overridden schema (corresponding to the respective schema Location defined). If this condition is not true, there’s no effect on the overriden schema location and overriding grammer won’t exist in the final schema representation.
2. a)Each and every <override> schema information element would be subjected to “override transformation”[5] . However when target namespaces of overriding and overridden schemas don’t match “chameleon inclusion transformation”[6] is also performed prior to the override transform. Override transformation itself is pervasive and therefore would be applied to <include> information items on the overridden schema.(ie:- if schema A overrides B and B includes C then C will also be overridden accordingly ).Further more override transformation also applies to <override> information items present on the overridden schema by merging the two <override> schema components.
- Although the idea behind xs:override seems to be rather simple , several scenarios need to be considered where some complications would inevitably arise.Following are several such considerations.
Circular includes and overrides would end up creating duplicate components that should be flagged as errors . (ie:- if Schema A include B , B override C and C intern include B then we could endup with different versions of B included in both A and C . Versions of B included in A and C will only be considered same if C->B override transformation does not apply ) . .
This scenario could occur in circular overrides as well (ie:- if schema A overrides B and B overrides A , then if B->A override transformation affects schema A then duplicate errors will occur) . .
In general if overriding schemas produce same/identical override transformation schema results for inclusion, then they would be considered the same , other wise if the transformation results differ , duplicates will occur .(ie:- If schema A includes B,C and B,C both inturn override D ,then B,C would include same version of D if B->D and C->D override transform doesn’t affect D OR if B,C both have the same override schema components )
- Implementation of xs:override should take into account the aforementioned factors so that dependencies are correctly evaluated and necessary schema preprocessing is performed.
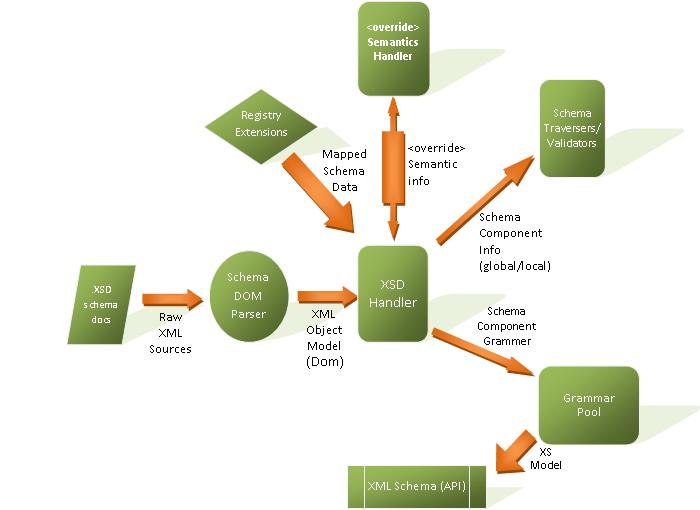
- Xerces2-j XMLSchema processing and supporting structures are mainly handled by classes located in org.apache.xerces.impl.xs package. Primarily XMLSchemaFactory and XMLScehmaLoader are responsible for loading(ie:- #loadGrammar() ) and handling schemas from a set of sources. Actually XMLSchemaLoader acts as an wrapper that provides necessary inputs for a XSDHandler (org.apache.xerces.impl.xs.traversers) instance which will inturn be coordinating the construction of a grammar object corresponding to a schema throughout several stages. XSDHandler instance is responsible for parsing each schema source (including the ones’s that are imported resulting in other grammers) , preprocessing/resoving /loading grammers etc.
- XSDHandler#parseSchema() is responsible for coordinating these critical stages of schema composition which includes ,
- a) constructTrees – constructs XSschema objects .Attempts to resolve <include>,<redefine> schema components and builds a dependency map . .
- b) buildGlobalNameRegistries - builds registries for all globally-referenceable names. Keeps track of <redefine> component mapping for detecting duplicate collisions and redefine preprocessing .
- c) traverseSchemas – traverse globally declared elements with appropriate traverser object (ie:-SimpleType/ComplexType/Attribute traversers) ,validate and build the grammer accordingly.
- d) traverseLocalElements-Traverse all the deferred local elements
- e) resolving ID/Key references
- f) storing imported grammars and building the Grammer Pool and XML Schema Model.
- .
- xs:override implementation intends to extend this functionality to implement <override> structure semantics. Implementation would include extending the phase #constructingTrees to include necessary mappings for override schema components (ie:-creating a fOverride2XSDMap , to map override elements with respective schema documents ). In general modification to this phase can closely be related to <redefine> implementation and would include necessary control paths as and when needed. However most challenging task would be in extending next two phases (in #buildGlobalNameRegistries and #traverseSchemas ) when implementing xs:ovserride semantics. These two phases include depth-first traversal of schema dependencies (ie:-when schema A includes B , A depends on B and vice versa) built in the first phase ,for building primary and subordinate registries on global components , and for traversing them for validation , respectively.These are obviously very important in Implementation of xs:override and will require to extend them approprately with much emphasis on design aspects. Main design/implementation areas are ,
- .
- extending XSDHandler#checkForDuplicateNames() - to include necessary control paths for <override> semantics ,detecting the scenarios where duplicate collisions can occur and flagginf these errors appropriately.
- implementing XSDHandler#transformOverriddenComponents(currentSchema,childComponent,componentType,oldName,newName) - renaming/transforming overridden components taking into consideration overriding of <includes> and merging <overriding> components on respective schema locations
- extending XSDHandler#traverseSchemas() and traversers( org.apache.xerces.impl.xs.traversers) - to traverse override schema components , and also to take into account the behavior(ie:-implicit) of each individual traverser objects on the application of xs:override semantics.
- .
- Also several supporting structures will be needed so that <override> schema components will be identified during schema processing. For example extending of following class structures.
- . • org.apache.xerces.impl.xs.SchemaSymbols – keeps track of collection of symbols used in parsing Schema Grammer. Need to introduce new <override> grammer symbols to this.
- . • org.apache.xerces.impl.xs.XSDDescription - keeps track of all information specific to XML Schema grammars. This can be used to indicate the Schema processor that the current schema document is overridden by another schema document
- . Additionally xs:override implementation may require quite a few new components/data structures to be added to org.apache.xerces.impl.xs package inorder to handle different scenarios regarding <override> semantics (ie:-implicit <override> semantics handling,registry extensions, etc) as was described in the beginning.
- .
- . • org.apache.xerces.impl.xs.SchemaSymbols – keeps track of collection of symbols used in parsing Schema Grammer. Need to introduce new <override> grammer symbols to this.
- Implmentation
- Following is an abstract level view on the implementation of xs:override semantics as an extension to the current XML schema processing framework.
- .
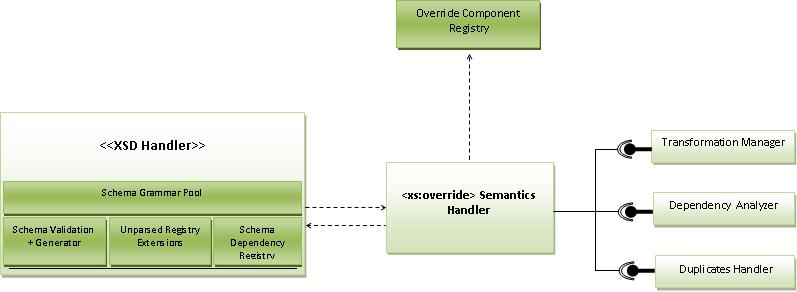
http://farm3.static.flickr.com/2803/4486137118_3aa3d2bb13_o.jpg - . XSD handler is the main component responsible for schema processing for Xerces-j . After successful implementation, the proposed extension (xs:override Semantics Handler) would seamlessly integrate into this current Schema processing framework so that <override> semantics can be applied on schema documents appropriately .The <xs:override> Handler component has three main sub components , namely “Transformation Manager” , “Dependency Analyzer” and “Duplicates Handler” .The primary sub-component , “Transformation Manager” have the task of applying necessary preprocessing and also override transformations on the respective schema components on which override semantics will be applied .It executes a very critical phase of <override> semantics implementation and indeed would pave the way for the actual schema generation.
Other sub-compnents , the ”Duplicates Handler” and “Dependency Analyzer” would come in to support the actions executed by “Transformation Manager” . Duplicates handler would provide necessary logic needed to detect duplicates and would try to handle them gracefully. “Dependency Analyzer” is also an important component since it would handle various tasks such as calculating [TargetSet]’s [3] of respective override components , supporting decisions of Duplicate Handler (ie:- in circular cases of overrides/includes ), etc . <xs:override> Semantics Component as a whole would be dependent on XSD Handler and vices versa during different stages of schema processing , so that aforementioned tasks can be successfully completed and ultimately the grammar pool is constructed with new <override> schema semantics included . The <override> semanitcs Handler will also keep a connection to the “Override Component Registry” constructed in the initial phases (ie:-construct trees phase) of schema processing ,which would map different <override> components with respective schema Documents that are implicitly/explicitly be affected by them .
- Implementation of these components need to take into account cyclic dependencies which could occur in <override> transformations. As discussed in the beginning these scenarios occur when the overriding paths go through a cycle of dependencies (ie:- include's) ,especially since <override> sematics inturn apply for included schemas. Each time “Transformation Manager” finds an included schama component it would transform that into a <override> component with "schemaLocation" being that of the included schema.However after applying necessary override transformations ,the respective <override> components(residing in overriding schema) would be replaced by <include>s pointing to the overriden schemas. For example if schema A overrides B which includes C and C inturn overrides A , the transformations would happen as follows. A will include B' (transformed/overriden version of B. ) , B' includes C' (transformed/overriden version of C) , C' includes A' (transformed/overriden version of A with merged overrides of both A and C ) and also similarly A' incl. B" ,B" incl. C" , C" incl. A" and so on. However at the point of including A' , if “Transformation Manager” sees that it differs with A then it would handle name collisions via "Duplicates Handler” logic. Otherwise it would continue to the point of including A" , where it would be notified of a cyclic dependency via “Dependency Analyzer” and would stop processing the cycle(since no point continuing the same cycle) and continue with the schema processing work that yet to be completed.
- Following is a very simplified data flow diagram indicating the general control flow of schema processing with the proposed <override> extension in place.As described earlier this shows how our proposed <override> Handler extension works with XSD Handler to produce desired schema grammer with necessary <override> sematics info applied.
- . .
http://farm5.static.flickr.com/4068/4486137116_4cb2ba4dc7_o.jpg - .
{kind=link}
{kind=link}
Things I have Done So far
- Since this project is about implementing a XMLSchema 1.1 specification construct , I had to go through this specification docs several times to understand the exact structure and semantics of the component I’m going to implement which I think is of vital importance when it comes to the design and implementation. Previous discussions (that has happened in Xerces-j-dev mail archives) about this xs:override support , online articles and tutorials also helped a lot in this cause. I also interacted with Xerces mailing list (especially with my mentor) to clarify critical points and implementation details. Since knowing Xerces and it’s internal framework(XNI) is obviously essential for the implementation I had to dig into various documentation, API information ,samples , regarding Xerces Design,architecture and especially XML schema processing. I did download the source code of Xerces2-j from trunk and build the code inorder to try and test out some samples to get a hang on the flow of things related to schema loading and processing.Running through several samples (xs.QuerryXS ,xni.GrammerBuilder, jaxp.SourceValidator, xni samples,etc) and debugging them , really gave me a good inisght into to Xerces framework. I also went through XML schema processing classes available in org.apache.xerces.impl.xs package to get a thorough understanding on exisiting schema processing framework and especially on how <redefine> semantics are applied to schema documents which is in some ways similar to <override> semantics._ _
Development Schedule
- I would initially focus on trying to come up with a good strategy to implement the proposed extension. For this i would need to digg into the existing framework on ways to integrate it correctly without breaking the existing code .I am planning to interact and discuss with the the xerces community (and with my mentor) on their suggestions and on any issues/bugs i may encounter along the way. After a good implementation strategy is in place i would start coding on it in several phases , taking into consideration different components of the proposed extension and their integration.Finally i will prepare the required test cases to validate the implemented extension and also the necessary design documentation,API java docs ,etc. I am willing to dedicate atleast 20-30 hours per week for the implementation of xs:overriding during the assigned four month GSoc period . If i get this project accepted , i am pretty much confident that during this time period i would successfully be able to complete the proposed implemenation with aforementioned milestones being achieved .
Time Schedule/Duration |
Activity |
March 18 - March 29 |
Initiate ideas ,discuss project details , get feed back on different aspects of the project,etc |
March 29 - April 9 |
preparing project proposals and submission |
April 26 |
GSoc Accepted student proposals announced by Google |
April 26 - May 24 (Community Bonding Period) |
preparation on design aspects,architecture on xs:overide implementaion; preraration on various platform details (ie:-xerces architecture,schema processing,etc) ; prepare development environment; |
May 24 - July 12 |
creating/finalizing necessary API's ; Start coding on xs:override implementation (creating required datastructures/registries ,implementing Trasformation Manager ,etc) |
July 12- July 16 |
Mid term Evaluations - students and mentors submit evaluations |
July 16 - August 9 |
start second phase of coding (implementing other sub components required); integration of xs:override implementation phases (if any) ; writing tests to validate xs:override semantics; |
August 9 - August 16 |
Final week of the project - final code submission on August 16th ; refine/review code ; finalizing documentaion , API docs; |
August 23 |
Final results of GSoc 2010 will be anounced |
_ _
Deliverables
- Source/patch related to xs:override implementation
- Solid set of test cases to verify related aspects of xs:override schema composition
- Documentation (java docs + design details) on xs:override implementation/API
Community Interaction
- Initially i had trouble selecting a project since the project i was keeping in mind was already undertaken. Xerces-2j mailing list was really helpfull in this ,giving me lot of feedback on available projects that was not even initally declared as Summer projects for 2010 . I was later able to get lot of insight on xs:override specification semantics and implementation details through the interaction on mails from xerces-j dev community . Through this I managed to digg into and clarify lot of details that would be very helpful through out my project and has definitely been a much needed guidance in writing this proposal as well. I am eagerly looking forward to work with Xerces community on this project and would like to make a positive contribution to Xerces-j team in every way i can.
About me
- I'm a Computer Science Engineering undergraduate (final year),of the department of Computer Science and Engineering, University of Moratuwa, Sri Lanka . I'm very much passionate about Computer science and am especially interested in subject areas related to Compiler Theory ,Distributed Systems and Enterprise Middelware and also Artificial Intelligence.I do have experience in open source development and related aspects and always loved working in such a dynamic and encouraging environment .
. I have worked on projects related to Apache Axis2 where I developed a tool [7](incubating) to extract WS-Policy(ie:-Security Policy) from WS policy compliant SOAP messages. This tool is especially useful in scenarios such as for clients who wish to build compatible client side policy for respective Services who don’t expose their messaging policy explicitly. This experience gave me a great understanding on WS:Security specifications and on mechanisms used by security modules such as Apache Rampart as well. Furthermore i have developed Axis2 Messaging and Service Level Infrastructure for Rubyscript [8], so that Ruby Scripts can be exposed and accessed via [WebServices] by clients .
. I also do have experience involved in projects related to Eclipse plugins, OSGi , XML parsers(this for our internal module DSD2.0[9] parser) and Data Mining (ie:-Collaborative Filtering), which got me working in a wide variety of frameworks ,programming/scripting languages such as Java ,C,C++, Javascript,Ruby,etc and under various platforms of Linux and Windows. I am currently involved in implementing a [TupleSpace] based Distributed System framework (which runs on top of a DHT[distributed hash table] named [FreePastry] [opensource implementation of Microsoft Pastry] ) for our final year project ,which facilitates time and space decoupling as well as content based addressing for messages in a distributed environment [10]. I consider my self a motivated computer science enthusiast who is willing to self learn and accept challenges and achieve them to the best of my ability. .
REFERENCES
[1] http://www.w3.org/TR/xmlschema-1/#key-fullyConforming![]()
[2] http://www.w3.org/TR/2006/REC-xml11-20060816/![]()
[3] http://www.w3.org/TR/xmlschema11-1/#override-schema![]()
[4] http://www.w3.org/TR/xmlschema11-1/#modify-schema![]()
[5] http://www.w3.org/TR/xmlschema11-1/#override-xslt![]()
[6] http://www.w3.org/TR/xmlschema11-1/#chameleon-xslt![]()
[7] https://wso2.org/repos/wso2/trunk/carbon/components/policy-builder![]()
[8] https://wso2.org/repos/wso2/trunk/carbon/components/jruby/![]()