1. Introduction
Apache Zeppelin is a web-based notebook that provides interactive data analysis. It is convenient for you to make beautiful documents that can be data-driven, interactive, and collaborative, and supports multiple languages, including Scala (using Apache Spark), Python (Apache Spark), SparkSQL, Hive, Markdown, Shell, and so on. Hive and SparkSQL currently support querying Hudi’s read-optimized view and real-time view. So in theory, Zeppelin’s notebook should also have such query capabilities.
2. Achieve the effect
2.1 Hive
2.1.1 Read optimized view

2.1.2 Real-time view

2.2 Spark SQL
2.2.1 Read optimized view

2.2.2 Real-time view

3. Common problems
3.1 Hudi package adaptation
Zeppelin will load the packages under lib by default when starting. For external dependencies such as Hudi, it is suitable to be placed directly under zeppelin / lib to avoid Hive or Spark SQL not finding the corresponding Hudi dependency on the cluster.
3.2 Parquet jar package adaptation
The parquet version of the Hudi package is 1.10, and the current parquet version of the CDH cluster is 1.9, so when executing the Hudi table query, many jar package conflict errors will be reported.
Solution:upgrade the parquet package to 1.10 in the spark / jars directory of the node where zepeelin is located.
Side effects:The tasks of saprk jobs other than zeppelin assigned to the cluster nodes of parquet 1.10 may fail.
Suggestions:Clients other than zeppelin will also have jar conflicts. Therefore, it is recommended to fully upgrade the spark jar, parquet jar and related dependent jars of the cluster to better adapt to Hudi’s capabilities.
3.3 Spark Interpreter adaptation
The same SQL using Spark SQL query on Zeppelin will have more records than the hive query.
Cause of the problem:When reading and writing Parquet tables to the Hive metastore, Spark SQL will use the Parquet SerDe (SerDe: Serialize / Deserilize for short) for Spark serialization and deserialization, not the Hive’s SerDe, because Spark SQL’s own SerDe has better performance.
This causes Spark SQL to only query Hudi’s pipeline records, not the final merge result.
Solution:setspark.sql.hive.convertMetastoreParquet=false
Method 1: Edit properties directly on the page

Method 2: Edit zeppelin / conf / interpreter.json and add
interpreter
"spark.sql.hive.convertMetastoreParquet": {
"name": "spark.sql.hive.convertMetastoreParquet",
"value": false,
"type": "checkbox"
},
4. Hudi incremental view
For Hudi incremental view, currently only supports pulling by writing Spark code. Considering that Zeppelin has the ability to execute code and shell commands directly on the notebook, later consider packaging these notebooks to query Hudi incremental views in a way that supports SQL.
HUDI-344
-
Getting issue details...
STATUS
has added an utility HoodieSnapshotExporter aims to facilitate exporting tasks for use-cases like backup copying and converting formats. In this blog, we illustrate its usage and features.
Copy to Hudi dataset
Similar to the existing HoodieSnapshotCopier, the Exporter scans the source dataset and then makes a copy of it to the target output path.
spark-submit \
--jars "packaging/hudi-spark-bundle/target/hudi-spark-bundle_2.11-0.6.0-SNAPSHOT.jar" \
--deploy-mode "client" \
--class "org.apache.hudi.utilities.HoodieSnapshotExporter" \
packaging/hudi-utilities-bundle/target/hudi-utilities-bundle_2.11-0.6.0-SNAPSHOT.jar \
--source-base-path "/tmp/" \
--target-output-path "/tmp/exported/hudi/" \
--output-format "hudi"
Export to json or parquet dataset
The Exporter can also convert the source dataset into other formats. Currently only "json" and "parquet" are supported.
spark-submit \
--jars "packaging/hudi-spark-bundle/target/hudi-spark-bundle_2.11-0.6.0-SNAPSHOT.jar" \
--deploy-mode "client" \
--class "org.apache.hudi.utilities.HoodieSnapshotExporter" \
packaging/hudi-utilities-bundle/target/hudi-utilities-bundle_2.11-0.6.0-SNAPSHOT.jar \
--source-base-path "/tmp/" \
--target-output-path "/tmp/exported/json/" \
--output-format "json" # or "parquet"
Re-partitioning
When export to a different format, the Exporter takes parameters to do some custom re-partitioning. By default, if neither of the 2 parameters below is given, the output dataset will have no partition.
--output-partition-field
This parameter uses an existing non-metadata field as the output partitions. All _hoodie_* metadata field will be stripped during export.
spark-submit \
--jars "packaging/hudi-spark-bundle/target/hudi-spark-bundle_2.11-0.6.0-SNAPSHOT.jar" \
--deploy-mode "client" \
--class "org.apache.hudi.utilities.HoodieSnapshotExporter" \
packaging/hudi-utilities-bundle/target/hudi-utilities-bundle_2.11-0.6.0-SNAPSHOT.jar \
--source-base-path "/tmp/" \
--target-output-path "/tmp/exported/json/" \
--output-format "json" \
--output-partition-field "symbol" # assume the source dataset contains a field `symbol`
The output directory will look like this
_SUCCESS symbol=AMRS symbol=AYX symbol=CDMO symbol=CRC symbol=DRNA ...
--output-partitioner
This parameter takes in a fully-qualified name of a class that implements HoodieSnapshotExporter.Partitioner. This parameter takes higher precedence than --output-partition-field, which will be ignored if this is provided.
An example implementation is shown below:
package com.foo.bar;
public class MyPartitioner implements HoodieSnapshotExporter.Partitioner {
private static final String PARTITION_NAME = "date";
@Override
public DataFrameWriter<Row> partition(Dataset<Row> source) {
// use the current hoodie partition path as the output partition
return source
.withColumnRenamed(HoodieRecord.PARTITION_PATH_METADATA_FIELD, PARTITION_NAME)
.repartition(new Column(PARTITION_NAME))
.write()
.partitionBy(PARTITION_NAME);
}
}
After putting this class in my-custom.jar, which is then placed on the job classpath, the submit command will look like this
spark-submit \
--jars "packaging/hudi-spark-bundle/target/hudi-spark-bundle_2.11-0.6.0-SNAPSHOT.jar,my-custom.jar" \
--deploy-mode "client" \
--class "org.apache.hudi.utilities.HoodieSnapshotExporter" \
packaging/hudi-utilities-bundle/target/hudi-utilities-bundle_2.11-0.6.0-SNAPSHOT.jar \
--source-base-path "/tmp/" \
--target-output-path "/tmp/exported/json/" \
--output-format "json" \
--output-partitioner "com.foo.bar.MyPartitioner"
Note that none of the _hoodie_* metadata field will be stripped; it is left to the user to deal with the metadata fields.
One of the core use-cases for Apache Hudi is enabling seamless, efficient database ingestion to your data lake. Even though a lot has been talked about and even users already adopting this model, content on how to go about this is sparse.
In this blog, we will build an end-end solution for capturing changes from a MySQL instance running on AWS RDS to a Hudi table on S3, using capabilities in the Hudi 0.5.1 release
We can break up the problem into two pieces.
- Extracting change logs from MySQL : Surprisingly, this is still a pretty tricky problem to solve and often Hudi users get stuck here. Thankfully, at-least for AWS users, there is a Database Migration service (DMS for short), that does this change capture and uploads them as parquet files on S3
- Applying these change logs to your data lake table : Once there are change logs in some form, the next step is to apply them incrementally to your table. This mundane task can be fully automated using the Hudi DeltaStreamer tool.
The actual end-end architecture looks something like this.
Let's now illustrate how one can accomplish this using a simple orders table, stored in MySQL (these instructions should broadly apply to other database engines like Postgres, or Aurora as well, though SQL/Syntax may change)
CREATE DATABASE hudi_dms; USE hudi_dms; CREATE TABLE orders( order_id INTEGER, order_qty INTEGER, customer_name VARCHAR(100), updated_at TIMESTAMP DEFAULT NOW() ON UPDATE NOW(), created_at TIMESTAMP DEFAULT NOW(), CONSTRAINT orders_pk PRIMARY KEY(order_id) ); INSERT INTO orders(order_id, order_qty, customer_name) VALUES(1, 10, 'victor'); INSERT INTO orders(order_id, order_qty, customer_name) VALUES(2, 20, 'peter');
In the table, order_id is the primary key which will be enforced on the Hudi table as well. Since a batch of change records can contain changes to the same primary key, we also include updated_at and created_at fields, which are kept upto date as writes happen to the table.
Extracting Change logs from MySQL
Before we can configure DMS, we first need to prepare the MySQL instance for change capture, by ensuring backups are enabled and binlog is turned on.


Now, proceed to create endpoints in DMS that capture MySQL data and store in S3, as parquet files.
- Source hudi-source-db endpoint, points to the DB server and provides basic authentication details
- Target parquet-s3 endpoint, points to the bucket and folder on s3 to store the change logs records as parquet files


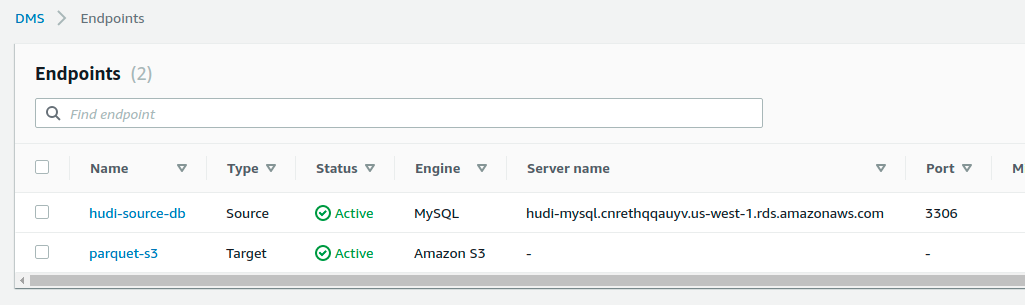
Then proceed to create a migration task, as below. Give it a name, connect the source to the target and be sure to pick the right Migration type as shown below, to ensure ongoing changes are continuously replicated to S3. Also make sure to specify, the rules using which DMS decides which MySQL schema/tables to replicate. In this example, we simply whitelist orders table under the hudi_dms schema, as specified in the table SQL above.


Starting the DMS task and should result in an initial load, like below.

Simply reading the raw initial load file, shoud give the same values as the upstream table
scala> spark.read.parquet("s3://hudi-dms-demo/orders/hudi_dms/orders/*").sort("updated_at").show
+--------+---------+-------------+-------------------+-------------------+
|order_id|order_qty|customer_name| updated_at| created_at|
+--------+---------+-------------+-------------------+-------------------+
| 2| 10| peter|2020-01-20 20:12:22|2020-01-20 20:12:22|
| 1| 10| victor|2020-01-20 20:12:31|2020-01-20 20:12:31|
+--------+---------+-------------+-------------------+-------------------+
Applying Change Logs using Hudi DeltaStreamer
Now, we are ready to start consuming the change logs. Hudi DeltaStreamer runs as Spark job on your favorite workflow scheduler (it also supports a continuous mode using --continuous flag, where it runs as a long running Spark job), that tails a given path on S3 (or any DFS implementation) for new files and can issue an upsert to a target hudi dataset. The tool automatically checkpoints itself and thus to repeatedly ingest, all one needs to do is to keep executing the DeltaStreamer periodically.
With an initial load already on S3, we then run the following command (deltastreamer command, here on) to ingest the full load first and create a Hudi dataset on S3.
spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \ --packages org.apache.spark:spark-avro_2.11:2.4.4 \ --master yarn --deploy-mode client \ hudi-utilities-bundle_2.11-0.5.1-SNAPSHOT.jar \ --table-type COPY_ON_WRITE \ --source-ordering-field updated_at \ --source-class org.apache.hudi.utilities.sources.ParquetDFSSource \ --target-base-path s3://hudi-dms-demo/hudi_orders --target-table hudi_orders \ --transformer-class org.apache.hudi.utilities.transform.AWSDmsTransformer \ --payload-class org.apache.hudi.payload.AWSDmsAvroPayload \ --hoodie-conf hoodie.datasource.write.recordkey.field=order_id,hoodie.datasource.write.partitionpath.field=customer_name,hoodie.deltastreamer.source.dfs.root=s3://hudi-dms-demo/orders/hudi_dms/orders
A few things are going on here
- First, we specify the --table-type as COPY_ON_WRITE. Hudi also supports another MERGE_ON_READ type you can use if you choose from.
- To handle cases where the input parquet files contain multiple updates/deletes or insert/updates to the same record, we use updated_at as the ordering field. This ensures that the change record which has the latest timestamp will be reflected in Hudi.
- We specify a target base path and a table table, all needed for creating and writing to the Hudi table
- We use a special payload class - AWSDMSAvroPayload , to handle the different change operations correctly. The parquet files generated have an Op field, that indicates whether a given change record is an insert (I), delete (D) or update (U) and the payload implementation uses this field to decide how to handle a given change record.
- You may also notice a special transformer class AWSDmsTransformer , being specified. The reason here is tactical, but important. The initial load file does not contain an Op field, so this adds one to Hudi table schema additionally.
- Finally, we specify the record key for the Hudi table as same as the upstream table. Then we specify partitioning by customer_name and also the root of the DMS output.
Once the command is run, the Hudi table should be created and have same records as the upstream table (with all the _hoodie fields as well).
scala> spark.read.format("org.apache.hudi").load("s3://hudi-dms-demo/hudi_orders/*/*.parquet").show
+-------------------+--------------------+------------------+----------------------+--------------------+--------+---------+-------------+-------------------+-------------------+---+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|order_id|order_qty|customer_name| updated_at| created_at| Op|
+-------------------+--------------------+------------------+----------------------+--------------------+--------+---------+-------------+-------------------+-------------------+---+
| 20200120205028| 20200120205028_0_1| 2| peter|af9a2525-a486-40e...| 2| 10| peter|2020-01-20 20:12:22|2020-01-20 20:12:22| |
| 20200120205028| 20200120205028_1_1| 1| victor|8e431ece-d51c-4c7...| 1| 10| victor|2020-01-20 20:12:31|2020-01-20 20:12:31| |
+-------------------+--------------------+------------------+----------------------+--------------------+--------+---------+-------------+-------------------+-------------------+---+
Now, let's do an insert and an update
INSERT INTO orders(order_id, order_qty, customer_name) VALUES(3, 30, 'sandy'); UPDATE orders set order_qty = 20 where order_id = 2;
This will add a new parquet file to the DMS output folder and when the deltastreamer command is run again, it will go ahead and apply these to the Hudi table.
So, querying the Hudi table now would yield 3 rows and the hoodie_commit_time accurately reflects when these writes happened. You can notice that order_qty for order_id=2, is updated from 10 to 20!
+-------------------+--------------------+------------------+----------------------+--------------------+---+--------+---------+-------------+-------------------+-------------------+ |_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name| Op|order_id|order_qty|customer_name| updated_at| created_at| +-------------------+--------------------+------------------+----------------------+--------------------+---+--------+---------+-------------+-------------------+-------------------+ | 20200120211526| 20200120211526_0_1| 2| peter|af9a2525-a486-40e...| U| 2| 20| peter|2020-01-20 21:11:47|2020-01-20 20:12:22| | 20200120211526| 20200120211526_1_1| 3| sandy|566eb34a-e2c5-44b...| I| 3| 30| sandy|2020-01-20 21:11:24|2020-01-20 21:11:24| | 20200120205028| 20200120205028_1_1| 1| victor|8e431ece-d51c-4c7...| | 1| 10| victor|2020-01-20 20:12:31|2020-01-20 20:12:31| +-------------------+--------------------+------------------+----------------------+--------------------+---+--------+---------+-------------+-------------------+-------------------+
A nice debugging aid would be read all of the DMS output now and sort it by update_at, which should give us a sequence of changes that happened on the upstream table. As we can see, the Hudi table above is a compacted snapshot of this raw change log.
+----+--------+---------+-------------+-------------------+-------------------+ | Op|order_id|order_qty|customer_name| updated_at| created_at| +----+--------+---------+-------------+-------------------+-------------------+ |null| 2| 10| peter|2020-01-20 20:12:22|2020-01-20 20:12:22| |null| 1| 10| victor|2020-01-20 20:12:31|2020-01-20 20:12:31| | I| 3| 30| sandy|2020-01-20 21:11:24|2020-01-20 21:11:24| | U| 2| 20| peter|2020-01-20 21:11:47|2020-01-20 20:12:22| +----+--------+---------+-------------+-------------------+-------------------+
Initial load with no Op field value , followed by an insert and an update.
Now, lets do deletes an inserts
DELETE FROM orders WHERE order_id = 2; INSERT INTO orders(order_id, order_qty, customer_name) VALUES(4, 40, 'barry'); INSERT INTO orders(order_id, order_qty, customer_name) VALUES(5, 50, 'nathan');
This should result in more files on S3, written by DMS , which the DeltaStreamer command will continue to process incrementally (i.e only the newly written files are read each time)

Running the deltastreamer command again, would result in the follow state for the Hudi table. You can notice the two new records and that the order_id=2 is now gone
+-------------------+--------------------+------------------+----------------------+--------------------+---+--------+---------+-------------+-------------------+-------------------+ |_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name| Op|order_id|order_qty|customer_name| updated_at| created_at| +-------------------+--------------------+------------------+----------------------+--------------------+---+--------+---------+-------------+-------------------+-------------------+ | 20200120212522| 20200120212522_1_1| 5| nathan|3da94b20-c70b-457...| I| 5| 50| nathan|2020-01-20 21:23:00|2020-01-20 21:23:00| | 20200120212522| 20200120212522_2_1| 4| barry|8cc46715-8f0f-48a...| I| 4| 40| barry|2020-01-20 21:22:49|2020-01-20 21:22:49| | 20200120211526| 20200120211526_1_1| 3| sandy|566eb34a-e2c5-44b...| I| 3| 30| sandy|2020-01-20 21:11:24|2020-01-20 21:11:24| | 20200120205028| 20200120205028_1_1| 1| victor|8e431ece-d51c-4c7...| | 1| 10| victor|2020-01-20 20:12:31|2020-01-20 20:12:31| +-------------------+--------------------+------------------+----------------------+--------------------+---+--------+---------+-------------+-------------------+-------------------+
Our little informal change log query yields the following.
+----+--------+---------+-------------+-------------------+-------------------+ | Op|order_id|order_qty|customer_name| updated_at| created_at| +----+--------+---------+-------------+-------------------+-------------------+ |null| 2| 10| peter|2020-01-20 20:12:22|2020-01-20 20:12:22| |null| 1| 10| victor|2020-01-20 20:12:31|2020-01-20 20:12:31| | I| 3| 30| sandy|2020-01-20 21:11:24|2020-01-20 21:11:24| | U| 2| 20| peter|2020-01-20 21:11:47|2020-01-20 20:12:22| | D| 2| 20| peter|2020-01-20 21:11:47|2020-01-20 20:12:22| | I| 4| 40| barry|2020-01-20 21:22:49|2020-01-20 21:22:49| | I| 5| 50| nathan|2020-01-20 21:23:00|2020-01-20 21:23:00| +----+--------+---------+-------------+-------------------+-------------------+
Note that the delete and update have the same updated_at, value. thus it can very well order differently here.. In short this way of looking at the changelog has its caveats. For a true changelog of the Hudi table itself, you can issue an incremental query.
And Life goes on ..... Hope this was useful to all the data engineers out there!
Deletes are supported at a record level in Hudi with 0.5.1 release. This blog is a "how to" blog on how to delete records in hudi. Deletes can be done with 3 flavors: Hudi RDD APIs, with Spark data source and with DeltaStreamer.
Delete using RDD Level APIs
If you have embedded HoodieWriteClient , then deletion is as simple as passing in a JavaRDD<HoodieKey> to the delete api.
// Fetch list of HoodieKeys from elsewhere that needs to be deleted // convert to JavaRDD if required. JavaRDD<HoodieKey> toBeDeletedKeys List<WriteStatus> statuses = writeClient.delete(toBeDeletedKeys, commitTime);
Deletion with Datasource
Now we will walk through an example of how to perform deletes on a sample dataset using the Datasource API. Quick Start has the same example as below. Feel free to check it out.
Step 1 : Launch spark shell
bin/spark-shell --packages org.apache.hudi:hudi-spark-bundle:0.5.1-incubating \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
Step 2 : Import as required and set up table name, etc for sample dataset
import org.apache.hudi.QuickstartUtils._ import scala.collection.JavaConversions._ import org.apache.spark.sql.SaveMode._ import org.apache.hudi.DataSourceReadOptions._ import org.apache.hudi.DataSourceWriteOptions._ import org.apache.hudi.config.HoodieWriteConfig._ val tableName = "hudi_cow_table" val basePath = "file:///tmp/hudi_cow_table" val dataGen = new DataGenerator
Step 3 : Insert data. Generate some new trips, load them into a DataFrame and write the DataFrame into the Hudi dataset as below.
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath);
Step 4 : Query data. Load the data files into a DataFrame.
val roViewDF = spark.
read.
format("org.apache.hudi").
load(basePath + "/*/*/*/*")
roViewDF.createOrReplaceTempView("hudi_ro_table")
spark.sql("select count(*) from hudi_ro_table").show() // should return 10 (number of records inserted above)
val riderValue = spark.sql("select distinct rider from hudi_ro_table").show()
// copy the value displayed to be used in next step
Step 5 : Fetch records that needs to be deleted, with the above rider value. This example is just to illustrate how to delete. In real world, use a select query using spark sql to fetch records that needs to be deleted and from the result we could invoke deletes as given below. Example rider value used is "rider-213".
val df = spark.sql("select uuid, partitionPath from hudi_ro_table where rider = 'rider-213'")
// Replace the above query with any other query that will fetch records to be deleted.
Step 6 : Issue deletes
val deletes = dataGen.generateDeletes(df.collectAsList())
val df = spark.read.json(spark.sparkContext.parallelize(deletes, 2));
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(OPERATION_OPT_KEY,"delete").
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath);
Step 7 : Reload the table and verify that the records are deleted
val roViewDFAfterDelete = spark.
read.
format("org.apache.hudi").
load(basePath + "/*/*/*/*")
roViewDFAfterDelete.createOrReplaceTempView("hudi_ro_table")
spark.sql("select uuid, partitionPath from hudi_ro_table where rider = 'rider-213'").show() // should not return any rows
Deletion with HoodieDeltaStreamer
Deletion with HoodieDeltaStreamer takes the same path as upsert and so it relies on a specific field called "_hoodie_is_deleted" of type boolean in each record.
- If a record has the field value set to false or it's not present, then it is considered a regular upsert
- if not (if the value is set to true ), then its considered to be deleted record.
This essentially means that the schema has to be changed for the source, to add this field and all incoming records are expected to have this field set. We will be working to relax this in future releases.
Lets say the original schema is
{
"type":"record",
"name":"example_tbl",
"fields":[{
"name": "uuid",
"type": "String"
}, {
"name": "ts",
"type": "string"
}, {
"name": "partitionPath",
"type": "string"
}, {
"name": "rank",
"type": "long"
}
]}
To leverage deletion capabilities of DeltaStreamer, you have to change the schema as below.
{
"type":"record",
"name":"example_tbl",
"fields":[{
"name": "uuid",
"type": "String"
}, {
"name": "ts",
"type": "string"
}, {
"name": "partitionPath",
"type": "string"
}, {
"name": "rank",
"type": "long"
}, {
"name" : "_hoodie_is_deleted",
"type" : "boolean",
"default" : false
}
]}
Example incoming record for upsert
{"ts": 0.0, "uuid": "69cdb048-c93e-4532-adf9-f61ce6afe605", "rank": 1034, "partitionpath": "americas/brazil/sao_paulo", "_hoodie_is_deleted" : false}
Example incoming record that needs to be deleted
{"ts": 0.0, "uuid": "19tdb048-c93e-4532-adf9-f61ce6afe10", "rank": 1045, "partitionpath": "americas/brazil/sao_paulo", "_hoodie_is_deleted" : true}
These are one time changes. Once these are in, then the DeltaStreamer pipeline will handle both upserts and deletions within every batch. Each batch could contain a mix of upserts and deletes and no additional step or changes are required after this. Note that this is to perform hard deletion instead of soft deletion.
Very simple in just 2 steps.
Step 1: Extract new changes to users table in MySQL, as avro data files on DFS
// Command to extract incrementals using sqoop bin/sqoop import \ -Dmapreduce.job.user.classpath.first=true \ --connect jdbc:mysql://localhost/users \ --username root \ --password ******* \ --table users \ --as-avrodatafile \ --target-dir \ s3:///tmp/sqoop/import-1/users
Step 2: Use your fav datasource to read extracted data and directly “upsert” the users table on DFS/Hive
// Spark Datasource Import org.apache.hudi.DataSourceWriteOptions._ // Use Spark datasource to read avro Dataset<Row> inputDataset spark.read.avro(‘s3://tmp/sqoop/import-1/users/*’); // save it as a Hudi dataset inputDataset.write.format(“org.apache.hudi”) .option(HoodieWriteConfig.TABLE_NAME, “hoodie.users”) .option(RECORDKEY_FIELD_OPT_KEY(), "userID") .option(PARTITIONPATH_FIELD_OPT_KEY(),"country") .option(PRECOMBINE_FIELD_OPT_KEY(), "last_mod") .option(OPERATION_OPT_KEY(), UPSERT_OPERATION_OPT_VAL()) .mode(SaveMode.Append); .save(“/path/on/dfs”)
Alternatively, you can also use the Hudi DeltaStreamer tool with the DFSSource.
Hudi hive sync tool typically handles registration of the dataset into Hive metastore. In case, there are issues with quickstart around this, following page shows commands that can be used
to do this manually via beeline.
Add in the packaging/hoodie-hive-bundle/target/hoodie-hive-bundle-0.4.6-SNAPSHOT.jar, so that Hive can read the Hudi dataset and answer the query.
hive> set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; hive> set hive.stats.autogather=false; hive> add jar file:///path/to/hoodie-hive-bundle-0.4.6-SNAPSHOT.jar; Added [file:///path/to/hoodie-hive-bundle-0.4.6-SNAPSHOT.jar] to class path Added resources: [file:///path/to/hoodie-hive-bundle-0.4.6-SNAPSHOT.jar]
Then, you need to create a __ReadOptimized__ Hive table as below (only type supported as of now)and register the sample partitions
drop table hoodie_test; CREATE EXTERNAL TABLE hoodie_test(`_row_key` string, `_hoodie_commit_time` string, `_hoodie_commit_seqno` string, rider string, driver string, begin_lat double, begin_lon double, end_lat double, end_lon double, fare double) PARTITIONED BY (`datestr` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'com.uber.hoodie.hadoop.HoodieInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' LOCATION 'hdfs:///tmp/hoodie/sample-table'; ALTER TABLE `hoodie_test` ADD IF NOT EXISTS PARTITION (datestr='2016-03-15') LOCATION 'hdfs:///tmp/hoodie/sample-table/2016/03/15'; ALTER TABLE `hoodie_test` ADD IF NOT EXISTS PARTITION (datestr='2015-03-16') LOCATION 'hdfs:///tmp/hoodie/sample-table/2015/03/16'; ALTER TABLE `hoodie_test` ADD IF NOT EXISTS PARTITION (datestr='2015-03-17') LOCATION 'hdfs:///tmp/hoodie/sample-table/2015/03/17'; set mapreduce.framework.name=yarn;
And you can add a __Realtime__ Hive table, as below
DROP TABLE hoodie_rt; CREATE EXTERNAL TABLE hoodie_rt( `_hoodie_commit_time` string, `_hoodie_commit_seqno` string, `_hoodie_record_key` string, `_hoodie_partition_path` string, `_hoodie_file_name` string, timestamp double, `_row_key` string, rider string, driver string, begin_lat double, begin_lon double, end_lat double, end_lon double, fare double) PARTITIONED BY (`datestr` string) ROW FORMAT SERDE 'com.uber.hoodie.hadoop.realtime.HoodieParquetSerde' STORED AS INPUTFORMAT 'com.uber.hoodie.hadoop.realtime.HoodieRealtimeInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' LOCATION 'file:///tmp/hoodie/sample-table'; ALTER TABLE `hoodie_rt` ADD IF NOT EXISTS PARTITION (datestr='2016-03-15') LOCATION 'file:///tmp/hoodie/sample-table/2016/03/15'; ALTER TABLE `hoodie_rt` ADD IF NOT EXISTS PARTITION (datestr='2015-03-16') LOCATION 'file:///tmp/hoodie/sample-table/2015/03/16'; ALTER TABLE `hoodie_rt` ADD IF NOT EXISTS PARTITION (datestr='2015-03-17') LOCATION 'file:///tmp/hoodie/sample-table/2015/03/17';