A way to implement (E)ERD components in Cassandra
Intro
This page describes model tranformations from (E)ERD concepts into Cassandra ColumnFamily concepts. All input is welcome.
I have created an implementation of the DBMS layer I describe in this article ThomasBoose dbms implementation. It not complete but it's a start.
DBMS layer
At several spots in this document you will find suggestions to implement trivial DBMS functionality by hand. At this stage, I would suggest to programmers to implement at least 4 tiers when using Cassandra as a back-end server. One would be the database layer by Cassandra itself, one would be a tier implementing DBMS rules, another for business rules finishing with an application tier.
In this DBMS tier, functions should be available for keeping data consistent based on datarules and it would throw exceptions when indexes are changed or orders are given to delete keys against DBMS rules.
If this is not yet making sense, continue reading.
Indexing
In order to add an index to a column, other than the ColumnFamily key, we should create a second ColumnFamily. Every insert, which can be either an insert or update in Cassandra, on the original ColumnFamily we will update the corresponding index.
Think of a ColumnFamily cf_Person (examples in Python using Pycassa)
cf_Person.insert('234', {'name':'Karel','City:'Haarlem'})
cfi_Person_City.insert ('Haarlem', {'234':''})
This way a hash will be created containing columns for every persons key that lives in a specific City. The ColumnFamily architecture of Cassandra can store an unlimited number of columns for each key. This means that when deleting a person, it's reference in the cfi_Person_City index should be removed first. When updating a person, maybe moving to another City, we have to remove the element from the cfi_Person_City first and then store it with the corresponding new City._ _
Deleting values
Because of the way Cassandra clusters operate it is nearly impossible to delete values and know for sure the values are deleted on every node. If values would simply be deleted and afterwards a node turns up which still holds the given value, it would replicate this value back to the existing nodes. Read more about deleting values at: DistributedDeletes
Cassandra on the other hand is isanely fast at inserting and updating values. This is why I would advise any programmer trying to build DBMS logic to introduce a value that 'means' deleted and have you DBMS tier respond "Does not exist" in both cases, when values actually do not exist or contain the 'deleted' value. Cassandra makes no distinction between updates and inserts so updating from 'deleted' and inserting can be achieved the same way.
Relations
1 on 1
Typically you'll find three kinds of 1 on 1 relations in a relational model. I will address them one at a time.
Equal elements
Sometimes all the elements are part of both collections on either side of the relationship. The reasons these collections are modelled seperately are most often based on security issues or functional differences. One solution in a Cassandra database would be the same as you would implement such a relation in an RDBMS. Simply by sharing the same key in both ColumnFamily's. Inserting a key in one of these ColumnFamily's would insert the same in the other and vise versa. Updating an existing key in either ColumnFamily would not result in any change in the other. Deleting a key from one ColumnFamily will result in deleting the same key in the other family as well, providing this would be allowed.
I'm not sure to what detaillevel security rules can apply in a Cassandra database. At least I know that one can create logins per cluster.
If it is necessary to use different keys for both collections, sometimes it is not up to one designer to select both keys, although the number of elements are equal and they are related one on one, in a relational model the designer gets to select either key to insert into the other collection with a unique and foreign key constraint.
{kind=link}
In Cassandra modelling you are forced to either crosslink both keys, so you'd design both keys foreign in both ColumnFamily's. Or you create a third ColumnFamily in which you store both keys preceded by a token to which ColumnFamily you are referring to. Let's focus on the first option. Say we hand out phones to our employees and we agree that every employee will always have one phone. And phones that are not used are not stored in our database. The phone has a phonenumber as key where the employee has a social security number. In order to know which number to dial when looking for employee X and who is calling giving a specific phonenumber, we need to store both keys foreign in both ColumnFamily's.
|
CF_Employee * * |
|
|
123-12-1234 |
name |
phone |
salary |
John |
0555-123456 |
10.000 |
|
321-21-4321 |
name |
phone |
salary |
Jane |
0555-654321 |
12.000 |
|
CF_Phone * * |
|
0555-123456 |
employee |
credit |
123-12-1234 |
10 |
|
0555-654321 |
employee |
credit |
321-21-4321 |
5 |
Using a static columnname and requiring input in the foreign key fields, checking the existence of the key in the other ColumnFamily and processing updates and deletes are all subject to programming in the DBMS layer. Cassandra itself does not, and probably will not, provide foreign key logic. One could imagine a process that makes sure the cross references stay consistent:
cf_Employee.insert('321-21-4321', {'name':'Jane', 'phone':'0555-654321'})
if cf_Phone.multiget('0555-654321', columns='employee') == {}:
cf_Phone.insert ('0555-654321', {'employee':'321-21-4321'})
else:
if cf_Phone.get('0555-654321', columns='employee')["Employee"] <> '321-21-4321':
raise error or delete specified employee
Subset elements
One on one relationships with one collection being smaller, in fact being a subset of the other collections in relational systems are solved by adding the key of the larger collection as foreign key to the smaller one. Preferably one uses the same key values as decribed above. This way we prevent null values that are not strictly indicating an unknown value. Null value's should only mean "We know there is a value but the value is unknown" as we've all learned in school.
http://boose.nl/images/specialisation.jpeg
{kind=link}
As stated we prefer the foreign key to be the same value as the key from the superset ColumnFamily. In every other case we'll have to introduce logic to keep the relation consistent. In any case you have to enforce the existance of all keys in the subset in the superset. Logic must also be provided when deleting elements from the superset with respect to the related element in the subset. These kind of relationships are also found in specialisations. The given example can be viewed as a single non total specialisation.
In order to create a disjunct specialisation one should add a column to the employee ColumnFamily containing a reference to a single subset ColumnFamily. Logic has to be introduced to keep your data consitent. I would again suggest to implement this logic in a DBMS tier.
Overlap
The easiest one on one relation to implement is the one in which elements in both collections do not need to be in the other but might. If at all possible create one big ColumnFamily that collects all elements from both collections and specialise to your intended ColumnFamily's, even if there is no corresponding attribute (column). If absolutly neccessary you can provide keys from either ColumnFamily if the values are not the same but one on one related. See above for constraint considerations.
1 to Many
In one to many relationships we add the key from the "one" side foreign to the "many" side. So if we're modelling students studying at only one school-unit at a time, we would add the unit's key to the student as foreign. Considering that no foreign key logic is provided you will have to write your own code to enforce consistancy in units existing, when the unit attribute of a student is set, and defining behaviour when deleting a unit. Considering the fact that this kind of relation is very common one could best create the logic for this at a seperate DBMS tier.
Every student has only one school-unit so we enforce one static name of a column that will reference this unit. For instance this column in the cf_Student ColumnFamily is called "school-unit". In a Cassandra database this is not sufficient to retrieve all student within this unit. One could find answers to questions like these but it would require quite a lot of processing power. If a ColumnFamily, the cf_School_unit family in this case, has only one of these relations, then one could choose to add all student keys to that ColumnFamily itself. I would not count on this situation persisting in future releases of your system and therefore suggest that you'd provide separate ColumnFamily's for each one to many relationship that you model.
This would lead to three ColumnFamily's
|
CF_Student * * |
|
|
123-12-1234 |
name |
unit |
city |
John |
SE |
The Hague |
|
321-21-4321 |
name |
unit |
city |
Jane |
SE |
Amsterdam |
|
CF_School_Unit * * |
|
SE |
name |
loc |
software engineering |
hsl |
|
CFK_School_Unit_Student * * |
|
SE |
123-12-1234 |
321-21-4321 |
|
|
No values are actually stored in the columns indicating the studentnumbers. These columns only exist to indicate which students are present in this unit.
If a one to many relationship contains itself attributes, which is perfectly acceptable in a (E)ERD model. One could be inspired to use SuperColumns. Cassandra SuperColumns are column that can contain columns themselves.
Many to Many
http://boose.nl/images/manytomany.jpeg
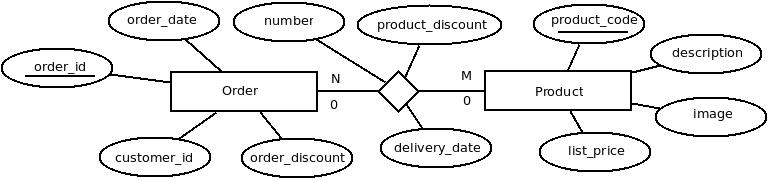{kind=link}
Let's look at a very basic part of an (E)ERD model. The power of Chen ERD models is that a lot of implicit information can be left out. Models should be simplified versions of their real life counterparts. No DBMS, relational nor NoSQL, can by itself implement many to many relationships. In Relational systems we would create a new table that would represent the relationship. This table would consist of both the keys (foreign keys) of the adjacent entities, being primairy together, supplemented with its own attributes.
As it is perfectly valid in a relational database to have a key value composed of several columns, in Cassandra there is only one key per ColumnFamily. I did already discuss the need to create seperate ColumnFamily's for one to many relationships given the fact that you can never tell for sure whether or not maybe in the future a new relation will pop up to another entity sharing the same keyvalues. This means that we will need 5 ColumnFamily's to implement the model above:
CF_Order is a straight forward ColumnFamily, modeled after the design.
|
CF_Order * * |
|
|
1234 |
order_date |
order_discount |
customer_id |
20100808 |
0.4 |
1234 |
|
4321 |
customer_id |
order_date |
|
3451 |
20100802 |
|
|
1354 |
order_discount |
order_date |
customer_id |
3 |
20100802 |
3451 |
The same for CF_Product
|
CF_Product * * |
|
|
DSK_SGT_5GB_7200 |
description |
image |
list_price |
5 GB Seagate harddisk |
|
130 |
|
KBD_LGT_WRL_350 |
description |
image |
list_price |
Wireless keyboard |
|
75 |
As we cannot iterate through a ColumnFamily based on any attribute except its key and we want to use a solution to relations that is generic. We create a seperate ColumnFamily for each one to many relationship. As we know that a many to many relationship is typically solved by introducing 2 one to many relationships to a newly created ColumnFamily. So there will be one ColumnFamily to store which orders a product can be found on.
|
CF_Product_Order * * |
|
|
DSK_SGT_5GB_7200 |
1234 |
4321 |
1354 |
|
|
|
|
KBD_LGT_WRL_350 |
4321 |
|
|
|
|
|
And we'll create one ColumnFamily that stores which products can be found on each order. We can see that this solution tends to invite anomalies. products that have 3 order columns but no reference to the product in the CF_Order_Product ColumnFamily. It up to the programmers of the DBMS tier to make sure generic code is available to keep the ColumnFamily's consistent all of the time.
|
CF_Order_Product |
|
|
1234 |
DSK_SGT_5GB_7200 |
|
|
|
|
|
|
4321 |
KBD_LGT_WRL_350 |
DSK_SGT_5GB_7200 |
|
|
|
|
|
1354 |
DSK_SGT_5GB_7200 |
|
|
|
|
|
- *Last but not least we'll introduce a ColumnFamily to store the attributes connected to the relationship between Product and Order. As mentioned it is not possible to create a key containing 2 separate values. So we'll have to introduce a new value that concatenates both values using a strict format. These formats should be part of a design if implementing a (E)ERD in Cassandra.
CF_order_line* *
1234_DSK_SGT_5GB_7200
number
delivery_date
5
20101215
4321_KBD_LGT_WRL_350
product_discount
number
delivery_date
0.3
1
20100901
4321_DSK_SGT_5GB_7200
product_discount
number
delivery_date
5
2
20100901
1354_DSK_SGT_5GB_7200
product_discount
number
delivery_date
5
8
20100901