Abstract
Sedona is a big geospatial data processing engine. The system provides an easy to use Scala, SQL, and Python APIs for spatial data scientists to manage, wrangle, and process geospatial data. The system extends and builds upon a popular cluster computing framework (Apache Spark) to provide scalability.
Proposal
Sedona builds upon the core engine of Apache Spark and SparkSQL to support spatial data types, indexes, queries and visualization at scale. Sedona is equipped with an out-of-the-box Spatial Resilient Distributed Dataset, which provides in-house support for distributed geospatial data partitioning and geospatial indexing. The Spatial RDD provides standard APIs for programmers to easily develop their spatial analysis programs using operational (Java, Scala, Python and R) and declarative (Spatial SQL) languages.
Sedona implements open standards to enable interoperability, e.g., OGC Simple Features for SQL standard. As the development continues, Sedona community will evaluate the implantation of new OGC API standards.
Sedona employs a spatial query processing layer that allows programmers to execute spatial query operators overloaded Spatial RDDs. Such a layer provides an efficient implementation of the most widely used spatial query operators, e.g., range filter, distance filter, spatial k-nearest neighbors, range join and distance join.
Sedona also comes with a map visualization layer that encapsulates the main steps of the geospatial map visualization process into a set of massively parallelized map building operators and allows users to declaratively generate a variety of map visualization effects. The geospatial visualization layer is compatible with Apache Zeppelin.
Background
Sedona was initially released in 2015 under the name of GeoSpark, by Data Systems Lab (https://www.datasyslab.net/) at Arizona State University. It was motivated by the need for large-scale geospatial data processing given the massive amount of available geospatial data. A number of researchers and engineers have been actively working on this project since then.
Rationale
The volume of available geospatial data has increased tremendously. Such data includes but is not limited to: weather maps, vegetation indices, geo-tagged social media, and more. Apache Spark is the de-facto cluster computing system for big data. Despite the popularity, it does not provide the native support for large-scale geospatial data processing and hence exhibits suboptimal performance in many relevant applications. In addition, it lacks standard geospatial processing APIs such as Spatial SQL, which hinders developers from easily integrating Spark into their existing geospatial data science pipelines.
Moreover, we plan to extend the project to support a variety of big data projects such as Apache Flink, Beam and Ignite because the research ideas proposed in Sedona (e.g., Spatial RDDs) are applicable or can be easily migrated to different platforms.
Therefore, we want to make Sedona as an independent project and advocate it as a big geospatial data processing engine. By adopting Sedona, Apache could build its impact on a variety of non-Computer Science disciplines including urban planning, transportation engineering and climate analytics.
Current Status
Sedona (now still named GeoSpark) started as a research project at Arizona State University and now becomes one of the most popular scalable geospatial data processing engines. We currently host its code on GitHub (https://github.com/DataSystemsLab/GeoSpark) and maintain its website periodically (https://datasystemslab.github.io/GeoSpark/). Sedona's binary code is also available on Maven Central (https://search.maven.org/search?q=g:org.datasyslab) and PyPi (https://pypi.org/project/geospark/).
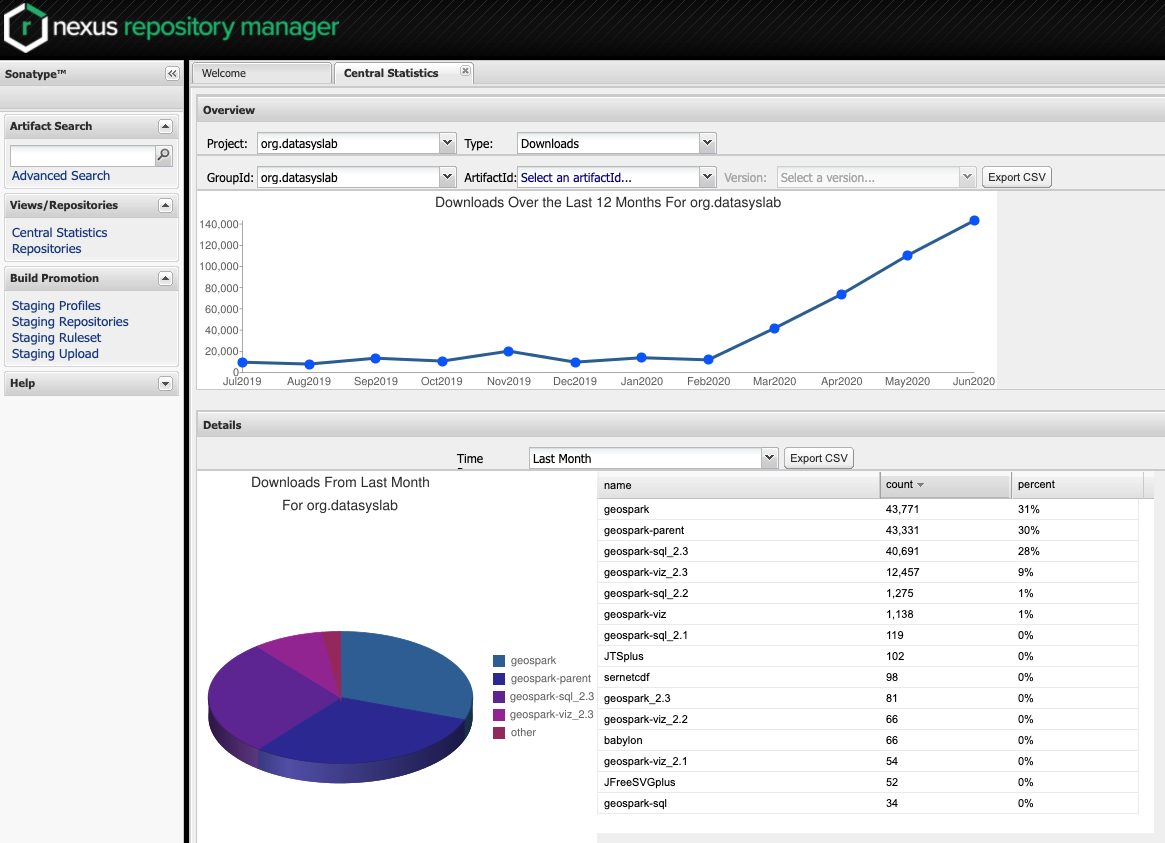
Sedona has users and contributors from many places all over the world including Facebook, Accenture, Bloomberg, MoBike, and GrabTaxi. In June 2020, its monthly downloads have reached 140K on Maven Central (https://jiayuasu.github.io/files/geospark-downloads.png) and 23K on PyPi (https://pypistats.org/packages/geospark).
{kind=link}
Meritocracy:
Sedona was initially developed by Jia Yu and Mohamed Sarwat at Arizona State University. Now, it has a total of 34 contributors; five of them who initially submitted substantial patches to the code repository and then were granted the commit privilege. It also has a number of contributors who have submitted a few patches. The project has clear contributing rules (https://datasystemslab.github.io/GeoSpark/contribute/rule/) and recognizes its contributors (https://datasystemslab.github.io/GeoSpark/contribute/contributor/).
In the future, we plan to set up a clear process for electing committers based on meritocracy and try our best to evolve our community by encouraging contribution.
Community:
Sedona pays lots of attention to its community. To foster a healthy community, Sedona has taken the following steps
Twitter account (https://twitter.com/GeoSpark_ASU): We use this account to periodically publish news about the development and applications of Sedona.
Discussion Board (https://groups.google.com/forum/#!forum/geospark-discussion-board): We use this forum to discuss use and development issues, although many users still tend to post questions on GitHub and Gitter.
Gitter Chat (https://gitter.im/geospark-datasys): We use this channel to run interactive communication among users and developers.
GitHub Issues (https://github.com/DataSystemsLab/GeoSpark/issues): We use GitHub Issues to track bug fixes and new feature development.
Our effort on this turns out to be a fruitful process. For example, the R language support of Sedona (https://github.com/harryprince/geospark) is from a community member Harry Zhu (Software Engineer at MoBike).
We expect all community channels to transition into Apache ones as we move into incubation.
On Github, Sedona has received 696 stars and 349 forks. In April 2020, its monthly downloads have reached 73K on Maven Central and 24K on PyPi (https://twitter.com/GeoSpark_ASU).
Core Developers:
The core developers of Sedona are from various backgrounds. The initial developers Jia Yu and Mohamed Sarwat are from Arizona State University. Soon after the initial release, developers from Facebook, Bloomberg, GrabTaxi, MoBike and Accenture have made several important patches to the project. A complete list of the contributors can be found on the website: https://datasystemslab.github.io/GeoSpark/contribute/contributor/
We have included several active developers beyond the first five in this Incubator proposal. To engage the community, we created a GitHub issue on GeoSpark repo to explain this donation in October 2019 https://github.com/DataSystemsLab/GeoSpark/issues/391. We posted an update of this proposal and added that if anyone found that we forgot them, we are more than happy to add them. We have contacted all code contributors individually through emails and personal contacts. They all support this donation. They are willing to continuously support this project. We believe that we have got strong support from the community.
Alignment:
We believe that Apache is the best place to take the Sedona project. Nowadays, the majority of the well-known big data projects stay in Apache, such as Hadoop, Spark, HIVE, and Flink. Sedona extends Apache Spark to bridge big data computing and GIS, and also uses Apache Hadoop as the underlying data storage. In addition, it provides a plugin for Apache Zeppelin to uphold interactive Sedona visualization notebooks. We also look for Apache-style development and aim at building a healthy community.
Geospatial data processing has always been a small but important part of the Apache community. For example, Apache SIS (https://sis.apache.org/) is an Apache project which provides a library of common geometrical operations. ApacheCon offers a geospatial track to gather fellow developers in this area (https://www.ogc.org/otherevents/apachecon-2019-geospatial-track).
By having this project adopted by Apache, we will have a broader impact on many disciplines and engage more non-Computer Science users and developers. In our opinion, this will be a good example to demonstrate how Apache, or Computer Science in general, has made our life better. Sedona team actually delivered a presentation in ApacheCon 2019 North America (https://apachecon.com/acna2019/s/#/scheduledEvent/1117) and had a meaningful communication with many Apache users and developers.
Known Risks
Project Name
The initial name of this project was GeoSpark. We decided to change the name to Sedona, which is a city in Arizona (the place where it all started). We believe this won't cause confusion in the future because we plan on advertising the new name to all the system users via our GitHub repo. We also plan to advertise the new name via well-known geospatial and data management mailing lists as well as developer forums.
Orphaned products
Currently, the project has received patches from many contributors but is being actively managed by a small number of committers to avoid any inconsistencies. We are aware of this problem and will work on it. The existing committers are very dedicated and the project is being used by many individuals and companies. This project is very unlikely to be orphaned. This is also why we want to join Apache to standardize our development and attract more active and long-term developers. We believe Sedona has the potential to become the de-facto open-source geospatial data processing platform.
Inexperience with Open Source:
Sedona started as an open-source project, GeoSpark, in 2015. Besides, since the early days of the project, we were keen to release the code under the Apache license. Over the years, the committers are quite familiar with the open-source procedure. We maintain a well-documented code and set up clear contribution rules. In addition, we collect feedback from the users and add new features on demand. A possible issue of this project is that we currently have no Apache members in our committers to help us understand the Apache-style development.
Length of Incubation:
We are aware that the project should learn the Apache-style development and build the community during the incubation process. We estimate the length of incubation to be one year, or longer. Since the project already has an active community, this will give the project sufficient time to migrate to the Apache infrastructure, improve the open-source procedure and fix the issues mentioned before.
Homogenous Developers:
This project already did a good practice of engaging developers from diverse backgrounds including individuals and companies. The current developers of Sedona come from different companies, universities and countries across the world. The background of the current developers can be found here: https://datasystemslab.github.io/GeoSpark/contribute/contributor/
The project will continue its effort on absorbing developers who are geographically distributed across the world. We are confident that the current community will become more diverse and healthy.
Reliance on Salaried Developers:
The initial contributors Jia Yu and Mohamed Sarwat started this project due to their own research interest. All subsequent developers voluntarily join the team because of their own interests. They have their daytime jobs and work on the project in their spare time. So far, we are not aware that any Sedona developers are paid by their companies to contribute to this project.
Relationships with Other Apache Products:
Sedona uses Apache Spark to achieve the scalability, calls Apache Hadoop for underlying data storage and depends on Apache Maven to build the project. It provides a plugin for Apache Zeppelin to uphold interactive Sedona visualization notebooks.
Moreover, as we grow the community, we look forward to future interfacing to other Apache big data projects such as Apache Flink, Beam, Ignite, etc.
A Excessive Fascination with the Apache Brand:
We surely acknowledge that the Apache brand has a strong impact and may attract more developers and users. But we also argue that the project itself already makes a good contribution to the existing geospatial data science community. Many users and developers have joined this project because they find that Sedona can solve many real-world issues in their day to day operations. Therefore, we strongly believe that joining Apache will be a win-win situation for both sides, Sedona and the Apache brand.
Documentation
https://datasystemslab.github.io/GeoSpark/
The current documentation is generated from source colocated with project source code.
Initial Source
We open-sourced Sedona in 2015 under the name GeoSpark. Currently, the source code is hosted on Github: https://github.com/DataSystemsLab/GeoSpark
The code is written in Java, Scala, Python and R. The license of Sedona was MIT license and changed to Apache license v2 in 2019.
Source and Intellectual Property Submission Plan
All the source code and documentation of Sedona are open-source and ready to be submitted to Apache. The license of Sedona was MIT license and changed to Apache license v2 in 2019. Both of these licenses are compatible with Apache.
External Dependencies:
Sedona has the following dependencies under Apache compatible licenses:
Apache license v2.0
Apache Spark
Apache Hadoop
ScalaTest (test only), not packaged in the released binary of Sedona
SerNetCDF, not packaged in the released binary of Sedona
AWS SDK For Java
MIT license
- org.wololo.jts2geojson
BSD license
Geotools: org.geotools.gt-main
GeoPandas
Eclipse Distribution License 1.0
- LocationTech JTS
Eclipse Public License v 1.0
- JUnit (test only), not packaged in the released binary of Sedona
Sedona has the following dependencies under Apache non-compatible licenses:
GNU LGPL
- GeoTools: we use its binary in Coordinate Reference System transformation. We will make this as an optional dependency and the default is off.
GNU GPL v2.0
- awt-color-factory: we use its binary to find the map colors defined by text instead of RGB color code. We will remove this dependency since we have alternative functions in the code.
Source code:
As all dependencies are managed using Apache Maven or Pip, none of the external libraries need to be packaged in a source distribution.
Binary:
To move to Apache, we will remove the non-compatible dependencies from the released binary files. We expect this to have a very limited impact on the users and the codebase:
The users will have the option to add these packages to their environment according to their own judgment.
These dependencies are rarely used in Sedona (less than 5%) and do not participate in the main logic of Sedona.
Cryptography:
N/A
Required Resources
Mailing lists:
private@sedona.incubator.apache.org (with moderated subscriptions)
dev@sedona.incubator.apache.org
commits@sedona.incubator.apache.org
Git Repositories:
https://gitbox.apache.org/repos/asf/incubator-sedona.git
JIRA Issue Tracking:
https://issues.apache.org/jira/browse/sedona
Initial Committers
The following is a list of the planned initial Sedona committers
Jia Yu (jiayu198910 AT gmail.com), Assistant Professor at Washington State University (USA)
Mohamed Sarwat (msarwat AT asu.edu), Assistant Professor at Arizona State University (USA)
Masha Basmanova (mbasmanova AT fb.com), Engineer at Facebook (USA)
Paweł Kociński (pawel93kocinski AT gmail.com), Engineer at Accenture (Poland)
Jinxuan Wu (jwu815 AT bloomberg.net), Engineer at Bloomberg (USA)
Zongsi zhang (zongsi.zhang AT grabtaxi.com), Engineer at GrabTaxi (Singapore)
Harry Zhu (7harryprince AT gmail.com), Engineer at MoBike (China)
Netanel Malka (netanelm AT sela.co.il), Engineer at Sela Group (Israel)
Affiliations
Sedona has more than 30 contributors. Here are the affiliations of some contributors. The others do not have known affiliations.
USA
Arizona State University
Mohamed Sarwat
Sagar Patni
Rishabh Mishra
Washington State University
- Jia Yu
- Masha Basmanova
Bloomberg
- Jinxuan Wu
Quantcast
- Omkar Kaptan
China
MoBike
- Harry Zhu
Guangzhou Urban Planning & Design Survey Research Institute
- Hui Wang
Poland
Accenture
- Paweł Kociński
Israel
Sela Group
- Netanel Malka
Singapore
GrabTaxi
- Zongsi Zhang
Vienna
Complexity Science Hub & Vienna University of Technology
- Georg Heiler
The project started at Arizona State University. Mohamed Sarwat is an assistant professor at ASU, with the remaining ASU affiliates being students or alumni.
Sponsors
Champion:
Felix Cheung (felixcheung AT apache.org)
Nominated Mentors:
Felix Cheung (felixcheung AT apache.org)
Jean-Baptiste Onofré (jbonofre AT apache DOT org)
George Percivall (percivall AT apache DOT org)
Von Gosling (vongosling AT apache DOT org)
Sponsoring Entity
Apache Incubator