整体思路
现在 iotdb 会因为自动参数优化将很小的数据块写入文件,使得数据文件变得零散化,这导致了用户进行即席查询时需要的读盘次数过多,而后期的合并过程又不是即时进行的,这导致了系统对热数据的查询效率变慢,所以我们借鉴了虚拟内存的思想,在写入流程中增加了合并过程,通过提高一部分写放大保证了写入到正式文件的数据块不小于给定阈值,提升系统即席查询的效率。将这部分逻辑写到 StorageGroupProcessor 里去,针对封口的 tsfile 文件进行合并。
* 配置修改
* iotdb-engine.properties 加一个参数 compaction_strategy:表示文件合并策略
* compaction_strategy 内置两个策略:LEVEL_COMPACTION 和 NO_COMPACTION
* LEVEL_COMPACTION 即开启合并并使用层级合并方法,NO_COMPACTION 即关闭合并
* iotdb-engine.properties 中加 merge_chunk_point_number:最大的chunk大小限制,LEVEL_COMPACTION 时,当达到该参数就合并到最后一层
* iotdb-engine.properties 加一个参数 max_level_num:LEVEL_COMPACTION 时最大层数
* 代码结构修改
* 新建一个 TsFileManagement 类,专门管理 StorageGroupProcessor 中的 seqFileList 和 unSeqFileList ,在这里写合并的主体逻辑,对外抽象对 seqFileList 和 unSeqFileList 的一系列所需接口
* 每一次合并会取第一个被合并文件的时间戳作为新文件的时间戳,即 {firstFileTimestamp}-{version}-{mergeVersion + 1}.tsfile
TsFileManagement 对外提供的接口和类
- TsFileManagement 也管理未封口文件
- TsFileManagement 同时管理 Seq 和 UnSeq 文件列表,在 StorageGroupProcessor 中只创建一个 TsFileManagement
- List\<TsFileResource\> getStableTsFileList() 对外提供稳定的 TsFileResource 列表
- List\<TsFileResource\> getTsFileList(boolean sequence) 对外提供(顺序/乱序)文件列表(如果 sequence = true,则提供按时间戳顺序的列表)
- Iterator\<TsFileResource\> getIterator(boolean sequence) 对外提供(顺序/乱序)文件迭代器(如果 sequence = true,则提供按时间戳顺序的迭代器)
- void remove(TsFileResource tsFileResource, boolean sequence) 删除对应的 TsFileResource 文件
- void removeAll(List\<TsFileResource\> tsfileReourceList, boolean sequence) 删除对应的 TsFileResource 列表
- void addAll(List\<TsFileResource\> tsfileReourceList, boolean sequence) 批量加入 TsFileResource 列表
- boolean isEmpty(boolean sequence) 是否为空
- int size(boolean sequence) 对应的文件列表长度
- void forkCurrentFileList(long timePartition) 保存当前文件的某时间分区列表
- void recover() 调用对应的恢复流程
- CompactionMergeTask 调用对应的异步合并流程,传入 closeUnsealedTsFileProcessorCallBack 以通知外部类合并结束
LEVEL_COMPACTION merge 流程
* 外部调用 forkCurrentFileList(long timePartition) 保存当前文件的某时间分区列表
* 这里选择的文件列表 chunk 点数之和不超出 merge_chunk_point_number
* 外部异步创建并提交 merge 线程
* 判断是否要进行乱序合并
* 调用原乱序合并逻辑,见 MergeManager 文档
* 判断是否要进行全局合并
* 生成目标文件 {first_file_name}-{max_level_num - 1}.tsfile
* 生成合并日志 .compaction.log
* 记录是全局合并
* 记录目标文件
* 进行合并(记录日志 device - offset)
* 记录完成合并
* 循环判断每一层的文件是否要合并到下一层
* 生成目标文件 {first_file_name}-{level + 1}.tsfile
* 生成合并日志 .compaction.log
* 记录是层级合并
* 记录目标文件
* 进行合并(每写完一个 device,记录日志 device - offset)
* 生成 .resource 文件
* writer endFile
* 记录完成合并
* 加写锁
* 从磁盘删掉待合并的文件,并从正式文件列表中移除
* 删除合并日志 .compaction.log
* 释放写锁
LEVEL_COMPACTION recover 流程
* 如果日志文件存在
* 如果是全局合并(把所有小文件合并到最后一层)
* 如果合并没结束且目标文件还未封口
* 截断文件
* 继续全局合并
* 删除原文件及其对应列表
* 如果是层级合并
* 如果合并没结束且目标文件还未封口
* 截断文件
* 继续层级合并
* 删除原文件及其对应列表
* 如果日志文件不存在
* 无需恢复
LEVEL_COMPACTION 例子
设置 max_file_num_in_each_level = 3,tsfile_manage_strategy = LevelStrategy, max_level_num = 3,此时文件结构为,第0层、第1层、第2层,其中第2层是不再做合并的稳定的文件列表
完全根据 level 合并的情况
假设此时整个系统中有5个文件,最后一个文件没有关闭,则其结构及顺序分布如下
level-0: t2-0 t3-0 t4-0
level-1: t0-1 t1-1
当最后一个文件关闭,按如下方式合并(第0层的t2-0、t3-0、t4-0文件合并到了第1层的t2-1文件)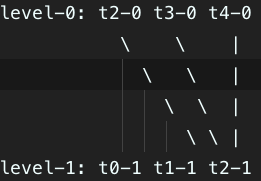
合并后发现第1层合并后也满了,则继续合并到第2层,最后整个系统只剩下了第2层的t0-2文件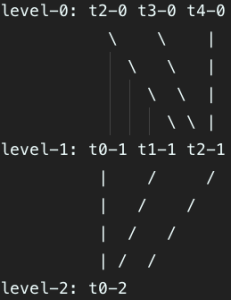
中途满足 merge_chunk_point_number 的情况
假设此时整个系统中有4个文件,最后一个文件没有关闭,则其结构及顺序分布如下
level-0: t2-0 t3-0
level-1: t0-1 t1-1
当最后一个文件关闭,但是t0-1、t1-1、t2-0、t3-0文件的 chunk point 数量加起来已经满足 merge_chunk_point_number,则做如下合并,即直接将所有文件合并到第2层(稳定层)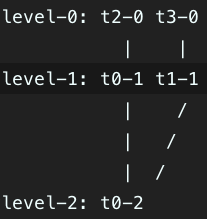
动态参数调整的例子
- 系统会严格按照上文中提到的 merge 流程对多层文件进行选择和合并,这里只介绍到参数调整时,系统初始化过程中文件会被放在哪一层
- 假设max_file_num_in_each_level = 3
* 从0.10.0升级
* 将所有文件的 mergeVersion 置为 {max_level_num - 1}
* 即老版本的文件不会被重复合并
假设整个系统中有5个文件,此时恢复后的文件结构为:
level-2: t0-2 t1-2 t2-2 t3-2 t4-2
* 提高 max_level_num
* 此时因为不会改变任何文件的原 level,所以 recover 时文件还会被放到原来的层上,或超出 {max_level_num - 1} 的文件被放在最后一层(考虑到多次调整的情况)
* 即原文件将基于原来的 level 继续合并,超出 {max_level_num - 1} 部分也不会有乱序问题,因为在最后一层的必然是老文件
假设整个系统中有5个文件,原 max_file_num_in_each_level = 2,提高后的 max_file_num_in_each_level = 3,此时恢复后的文件结构为:
level-0: t2-0 t3-0 t4-0
level-1: t0-1 t1-1
假设 {size(t2-0)+size(t3-0)+size(t4-0)< merge_chunk_point_number},则进行合并的过程如下
合并后发现第1层合并后也满了,则继续合并到第2层,最后整个系统只剩下了第2层的t0-2文件
* 降低 max_level_num
* 此时因为不会改变任何文件的原 level,所以 recover 时小于此时 {max_level_num - 1} 的文件还会被放到原来的层上,而超出的文件将被放在最后一层
* 即部分文件将被继续合并,而超出 {max_level_num - 2} 的文件将不会再被合并
假设整个系统中有7个文件,原max_file_num_in_each_level = 3,降低后的max_file_num_in_each_level = 2,此时恢复后的文件结构为:
level-0: t4-0 t5-0 t6-0
level-1: t0-2 t1-1 t2-1 t3-1
假设 {size(t2-0)+size(t3-0)+size(t4-0)< merge_chunk_point_number},则进行合并的过程如下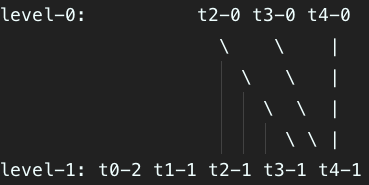
合并后发现第1层合并后也满了,则继续合并到第2层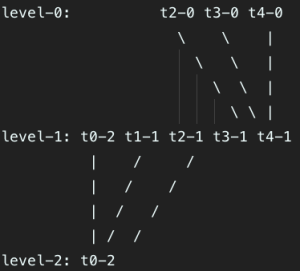
最后剩下的文件结构为
level-0:
level-1: t3-1 t4-1
level-2: t0-2
* NO_COMPACTION -> LEVEL_COMPACTION
* 此时因为因为删去了原始合并的 {mergeVersion + 1} 策略,所以所有文件将全部被放到0层
* 每一次合并会最多取出满足 {merge_chunk_point_number} 的文件进行合并,直到将所有多余的文件合并完,进入正常的合并流程
假设整个系统中有5个文件,此时恢复后的文件结构为:
level-2: t0-0 t1-0 t2-0 t3-0 t4-0
假设 {size(t0-0)+size(t1-0)>=merge_chunk_point_number},则进行第一次合并的过程如下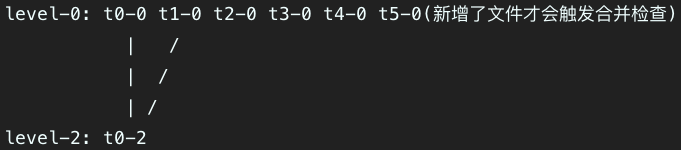
假设 {size(t2-0)+size(t3-0)>=merge_chunk_point_number},则进行第二次合并的过程如下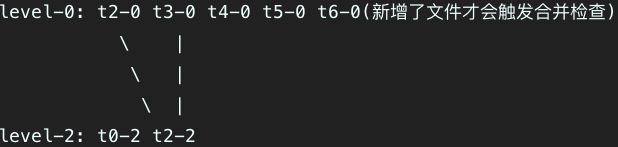
假设 {size(t4-0)+size(t5-0)+size(t6-0)+size(t7-0)< merge_chunk_point_number},则进行第三次合并的过程如下