...
- You need to have Apache Ant installed and configured on your system.
- Grab the newest version of Eclipse available here.
- All of the following should be available from the Eclipse Marketplace. However if not, you can download them throughout Eclipse as follows
Steps
...
Clone and Build Nutch
Get the latest source code using Git from the terminal. For Nutch 1.x (i.e. master branch) run this:
No Format git clone https://github.com/apache/nutch.git cd nutch
2. Add “httphttp.agent.name” name and “httphttp.robots.agents” agents with appropriate values in “confconf/nutch-site.xml”xml. See conf/nutch-default.xml for the description of these properties. Also, add “pluginplugin.folders” folders and set it to {PATH_TO_NUTCH_CHECKOUT}/build/plugins e. egg. If Nutch is present at "/home/tejas/Desktop/nutch", set the property to:No Format <property> <name>plugin.folders</name> <value>/home/tejas/Desktop/nutch/build/plugins</value> </property>
3. Run this command:No Format ant eclipse
...
- In Eclipse, click on “File” -> “Import...”
2. Select “Existing Projects into Workspace”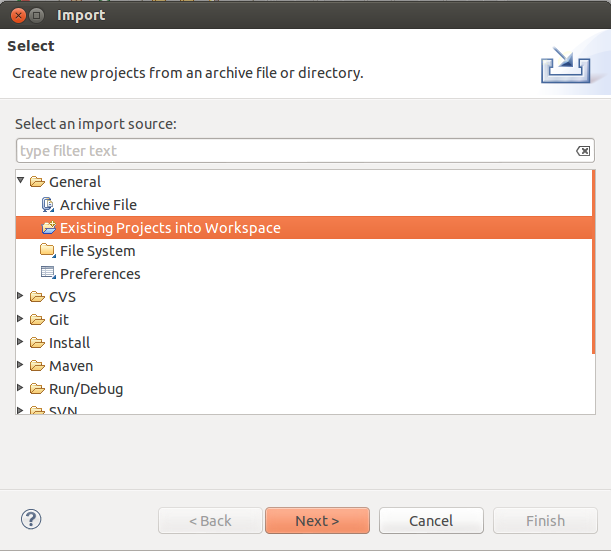
3. In the next window, set the root directory to the location where you took the checkout of nutch 2.x (or trunk)cloned Nutch master branch. Click “Finish”.
4. You will now see a new project named 2.x (or trunk) nutch being added in the workspace. Wait for a moment until Eclipse refreshes its SVN cache and builds its workspace. You can see the status at the bottom right corner of Eclipse.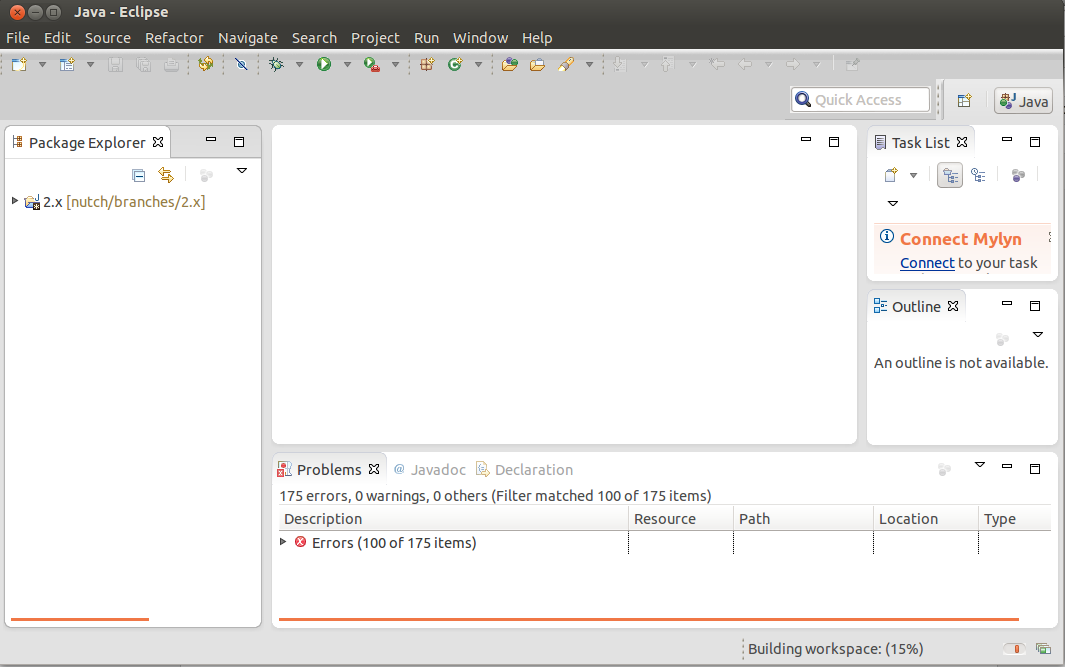
5. In Package Explorer, right click on the project “2.x” (or trunk)nutch, select “Build Path” -> “Configure Build Path”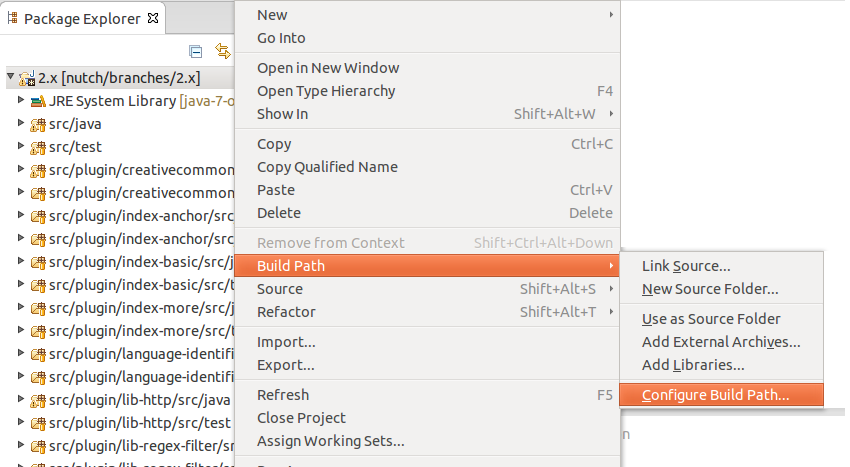
6. In the “Order and Export” tab, scroll down and select “2.x/conf” (or trunknutch/conf). Click on “Top” button. Sadly, Eclipse will again build the workspace but this time it won’t take take much.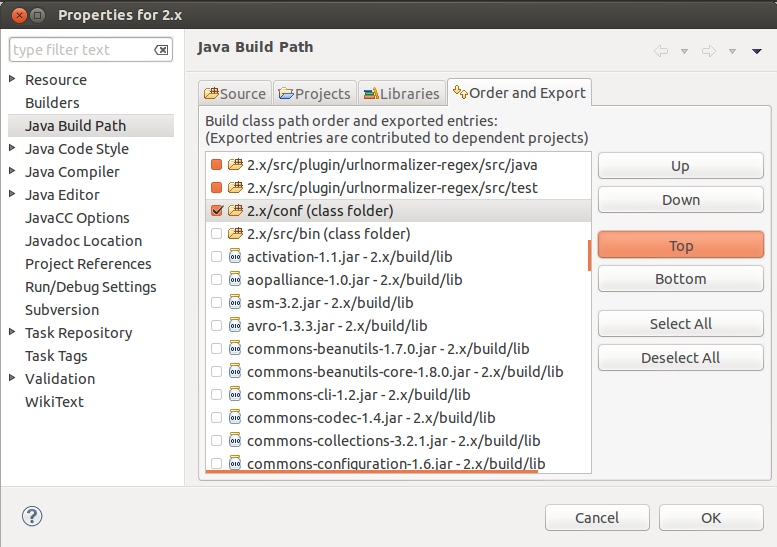
...
Now, lets get geared to run something. Lets start off with the inject operation. Right click on the project in “Package Explorer” -> select “Run As” -> select “Run Configurations”. Create a new configuration. Name it as "inject".
- For 1.x ie trunk : Set the main class as: org.apache.nutch.crawl.Injector
- For 2.x : Set the main class as: org.apache.nutch.crawl.InjectorJob
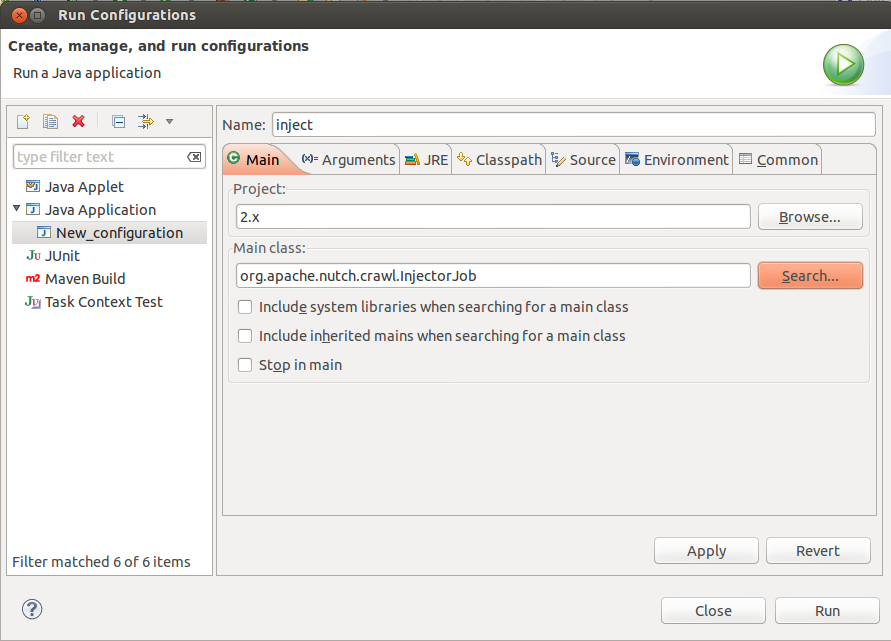
In the arguments tab, for program arguments, provide two Program arguments
- the path of the crawldb you wish to create i.e. /home/tejas/Desktop/nutch/crawldb, and
- the path of a directory containing seed urls i.e. /home/tejas/Desktop/nutch/urls
Additionally, you should set input directory which has seed urls. Set VM Arguments to “-Dhadoop.log.dir=logs -Dhadoop.log.file=hadoop.log”
...
Operation | Class in Nutch 1.x (i.e.trunk) | Class in Nutch 2.x |
inject | org.apache.nutch.crawl.Injectororg.apache.nutch.crawl.InjectorJob | |
generate | org.apache.nutch.crawl.Generator | org.apache.nutch.crawl.GeneratorJob |
fetch | org.apache.nutch.fetcher.Fetcher | org.apache.nutch.fetcher.FetcherJob |
parse | org.apache.nutch.parse.ParseSegment | org.apache.nutch.parse.ParserJob |
updatedb | org.apache.nutch.crawl.CrawlDborg.apache.nutch.crawl.DbUpdaterJob |
Debug Nutch in Eclipse
- Set breakpoints and debug a crawl
- It can be tricky to find out where to set the breakpoint, because of the Hadoop jobs.
- Here are a few good places to set breakpoints in the 1.x codebase:
| No Format |
|---|
Fetcher [line: 1115] - run Fetcher [line: 530] - fetch Fetcher$FetcherThread [line: 560] - run() Generator [line: 443] - generate Generator$Selector [line: 108] - map OutlinkExtractor [line: 71 & 74] - getOutlinks |
- Here are a few good places to set breakpoints in the 2.x codebase:
| No Format |
|---|
FetcherReducer$FetcherThread run() : line 487 : LOG.info("fetching " + fit.url ....
: line 519 : final ProtocolStatus status = output.getStatus();
GeneratorMapper : map() : line 53
GeneratorReducer : reduce() : line 53
OutlinkExtractor : getOutlinks() : line 84
|
Remote Debugging in Eclipse
...
| No Format |
|---|
% export NUTCH_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=localhost:37649" % $NUTCH_HOME/bin/nutch parsechecker http://myurl.com/ |
13. #3 the application will be suspended just after launch
4. now go to Eclipse, set appropriate break-points, and run the previously created Debug Configuration
Instead of creating an extra launch configuration for every tool you want to debug, one single configuration is enough to debug any tool (parsechecker, indexchecher, URL filter, etc.) and that even remotely (crawler/tool running on server, Eclipse debugger locally).
...
During unit testing, Eclipse ignored conf/nutch-site.xml in favor of src/test/nutch-site.xml, so you might need to add the plugin directory configuration to that file as well.
...
- Checkout the Hadoop version that should be used within Nutch trunkmaster branch. You can determine this version by checking ivy.xml.
- Configure a Hadoop project similar to the Nutch project within your Eclipse IDE. See this.
- Add the Hadoop project as a dependent project of Nutch project
- You can now also set break points within Hadoop classes like inputformat implementations etc.
Non-ported Plugins to 2.x
...